
Is every row in X (X=mnist[“data”]) is an image of 28x28 pixels
and if yes then why it is one dimensional
Hi, Ved.
Good question!
Data is only flattened when passed to a dense layer. This is because the internal architecture consists of weights matrix of a= (1 by n ) =[theta1, theta2, theta3, theta4, theta5, theta6…]
and we want to extract the information from each and every pixels so we flatten the inputs pixels matrix into (n by 1) matrix. let b =[pixel1, pixel2, pixel3, pixel4, pixel5, pixel6, pixel7…]
Now you can do the matrix multiplications and find out which inputs has what contributions.
on the other hand convolutional layers require the data to be 2D due to the fact that they learn image filters which are 2D matrices of weights which are passed over the image so no need to do flattened data.
It is already given in the Lecture.
All the best!
-
In precission and Recall why do we pass the second argument as y_train_pred the test set should be passed?
-
What is the differnce between cross_val_score and cross_val_predict?
-
What is OvO Strategy and OvA Strategy?
Hi,
Could you please help me by pointing out which slide you are referring to?
The cross_val_score() is the simplest way to make cross-validation using sklearn. Here the score is calculated the number of times which is defined by the cv parameter, each time with different splits. Using these results you can calculate simple measures like average value. By default, cross_val_score() uses the default score method of the estimator. Default score method of the estimator depends both on the model which you use and your type of data. So it is important to know what is the default score of your estimator. It is better to control score method. You can simple define it using scoring parameter.
The cross_val_predict() is not so compact solution. Results of it is the ‘cross-validated’ prediction for each observation which you pass as argument to this function. In other words, prediction is obtained for each element when it was in the test set. Then you can use these predictions to calculate cross-validation metric (which are directly delivered by cross_val_score()). In cross_val_predict() elements are grouped slightly different than in cross_val_score(). It means that when you will calculate the same metric using these functions, you can get different results.
The most common decomposition strategies include OVO and OVA . The former consists in using a binary classifier to discriminate between each pair of classes, while the latter, uses a binary classifier to distinguish between a single class and the remaining ones.
Hope this resolves your query.
Thanks.
Hi, Ved.
- The precision_recall_curve() inputs arguments are the True “class labels” and the “predicted probabilities” and the return values are precision, recall, and thresholds.
Directly we don’t put the test labels as inputs.
For example
Here it is how it works
a) predict probabilities from the test sets
pos_probs= model.predict_proba(testX).
b) Then we calculate model precision-recall curve by using these variables.
precision, recall, threshold = precision_recall_curve(y_test, pos_probs).
- a)
The "cross_val_score" use the "cross validation technique" to estimate the accuracy score of any estimators or predicting algorithm by
a) Splitting the input data into number of k-folds of the batch.
b) Then fits each batch or folds by computing the score of k-consecutive times with different splits at each iterations.
and then by seeing all these scores you can know your estimators or algo accuracy.
Sample snippets.
from sklearn.model_selection import cross_val_score
clf = svm.SVC(kernel=‘linear’, C=1)
scores = cross_val_score(clf, X, y, cv=5)
b) cross_validate
It is also used to find the accuracy of the estimator algorithms and also use the cross validations technique to find the scores.
----> The difference is that , in this we can define multiple metrics like precision, recall etc for evaluation..
---->It return [‘test_score’, ‘fit_time’, ‘score_time’] for all the metrics used and their computations time by that algorithms.
Note -->
The function cross_val_score takes an average over cross-validation folds, whereas cross_val_predict simply returns the labels (or probabilities) from several distinct models undistinguished so cross_val_predict is not a good measure of error as it won’t give us the perfect error measure compared to cross_val_score.
But it is good for Visualization of predictions obtained from different models.
In short.
**cross_val_score --> evaluate a score by cross-validation and **
cross_val_predict --> Evaluate metric(s) by cross-validation and also record fit/score times.
more read on :- cross_val_score() VS cross_val_predict()
https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation
- One-vs-One (OvO for short) :-
It is a method where we calculate the similarity with one entity with others one by one and splits it into a binary classification problem.
means let [“car”,“aeroplane”,“apple”, “lion”]
Split :- [“car”] vs ,[“aeroplane”]
[“car”] vs [“apple”]
[“car”] vs [“lion”]
[“aeroplane”] vs [“apple”]
[“aeroplane”] vs [“lion”]
[“apple”] vs [“lion”]
so here we need to compare each element with each other elements so total number of combinations possible is 4C2 ways = 6 ways.
Each binary classification model may predict one class label and the model with the most predictions or votes is predicted by the one-vs-one strategy.
One-vs-Rest (OvR for short) :-
It is a method where we splits the data into one and vs rest classes.
Then a binary classifier is then trained on each binary classification problem and predictions are made using the model that is the most confident.
means let [“car”,“aeroplane”,“apple”]
eg :- Split1:- [“car”] vs [“aeroplane”,“apple”].
Split2:- [“aeroplane”] vs [“apple”,“lion”].
Split3:- [“apple”] vs [“lion”, “car”].
It required three different models to calculate.
Note:- One vs One strategy is mostly used SVC.
More read on One vs One and One VS rest: https://scikit-learn.org/stable/modules/multiclass.html#ovr-classification
All the best!
1 ) Sir i understand that in OvR strategy (considering MNIST set) there will be 10 models so do we have to test our image on every model one by one?.
-
SIr in OvO Strategy there are 45 Binary Classifiers then which is the model?
-
How do we comw to know which clsddification algorithm to use to train model in classification?
-
Does selection of algorithm depends on the type of Classification if yes then which algorithm should be used for multilabel,multiclass
and multioutput classification? -
What is pipeline with example?
-
HOw do we come to know which classifier to use in different scenarios?
-
How do we come to know which classifier to use ?
Hi,
- One-vs-rest (OvR for short, also referred to as One-vs-All or OvA) is a heuristic method for using binary classification algorithms for multi-class classification. It involves splitting the multi-class dataset into multiple binary classification problems. A binary classifier is then trained on each binary classification problem and predictions are made using the model that is the most confident.
For example, given a multi-class classification problem with examples for each class ‘ red ,’ ‘ blue ,’ and ‘ green ‘. This could be divided into three binary classification datasets as follows:
- Binary Classification Problem 1 : red vs [blue, green]
- Binary Classification Problem 2 : blue vs [red, green]
- Binary Classification Problem 3 : green vs [red, blue]
In case of MNIST, instead of red,blue, and green, we have digits ranging from 0 - 9.
- One-vs-One (OvO for short) is another heuristic method for using binary classification algorithms for multi-class classification. Like one-vs-rest, one-vs-one splits a multi-class classification dataset into binary classification problems. Unlike one-vs-rest that splits it into one binary dataset for each class, the one-vs-one approach splits the dataset into one dataset for each class versus every other class.
Here, you choose the model. For example, if you want to use SVM, you can implement OvO in SVM as follows:
model = SVC(decision_function_shape='ovo')
- Here is a Machine Learning map from Scikit-learn that might help answer this point:
https://scikit-learn.org/stable/tutorial/machine_learning_map/
-
The explanation for points 1, and 2 should explain this point. Let me know if you need more details.
-
A pipeline is like a macro for Machine Learning, or a production line. You put in your input, which in most cases is the raw data, what comes out is the processed data. Say for example, you know your dataset has missing values, and needs to be standardized. You put both the codes for
SimpleImputerandStandardScalerin a pipeline, and instead of running your data separately through each one of them, you simply use the Pipeline. This makes it more compact. -
This should be explained by point 3.
-
This should be explained by point 3.
Apart from these, there is something in Machine Learning called No Free Lunch theorem. This basically states that no single solution offers a “short cut”, or there is no single solution that fits all.
Hope these answers your queries. Keep learning!
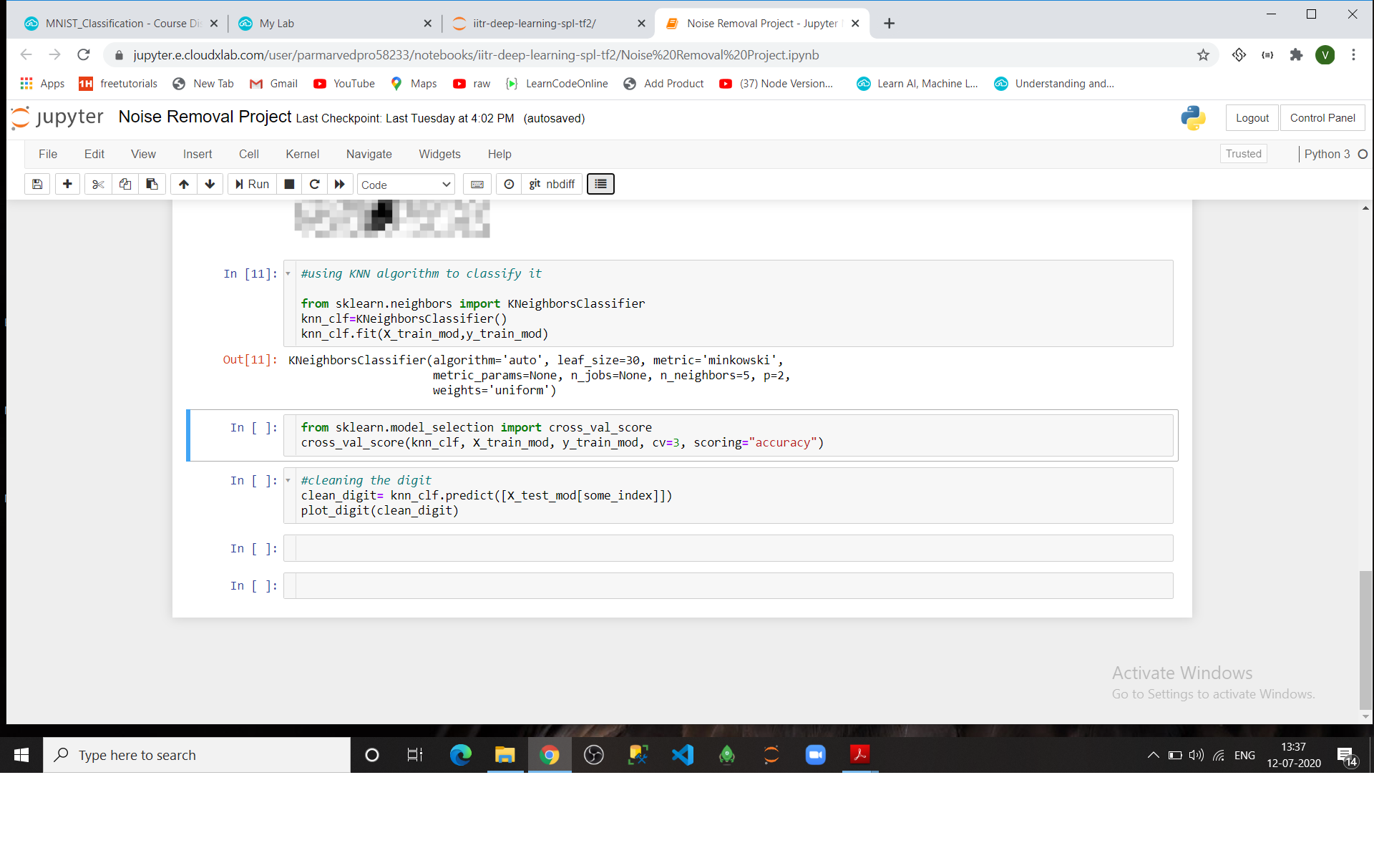
Hello Sir I am doing the project of MNIST Classification I am not able to calculate the cross_value_score or accuracy of model and when ever i rum that cell it gets disconnected and i am also confused where to add ramdom_value or seed ()
Please tell me how could i share my code
Hi,
Could you please share a screenshot?
Thanks.

Hi,
Please restart your server by following the steps from the below link and then try once again:
Also, could you please manually try to execute that cell. To do that you need to click inside the cell, and then press Shift+Enter.
Let me know if it worked.
Thanks.
Well Sir i havnt done this project on Assesment Engine i have done in a seprate jupyter notebook and as you said i also executed the cell manually still its getting disconnected while running cross_val_score cell which is in last image
Hi Ved,
Would request you to go through our Fair Usage Policy from the below link:
Also, you can go through the below discussions for a better understanding of the issue, and a probable solution:
Thanks.