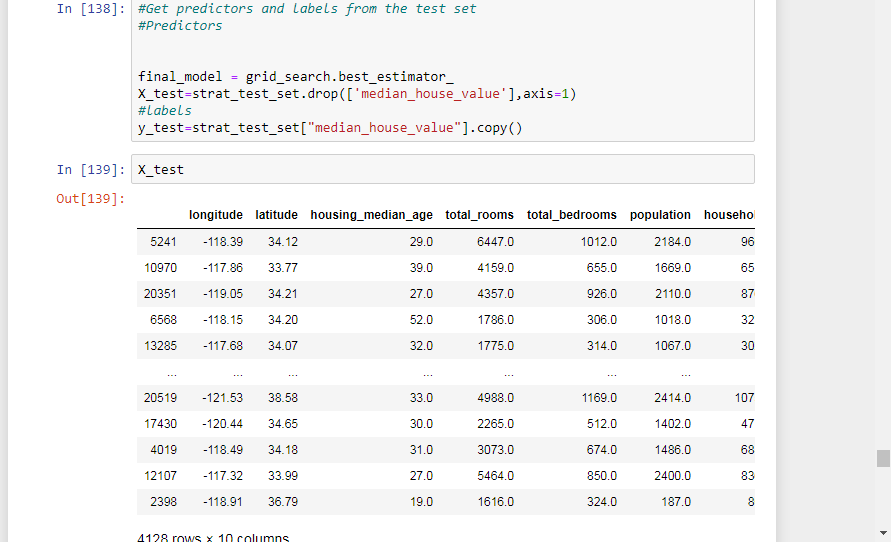
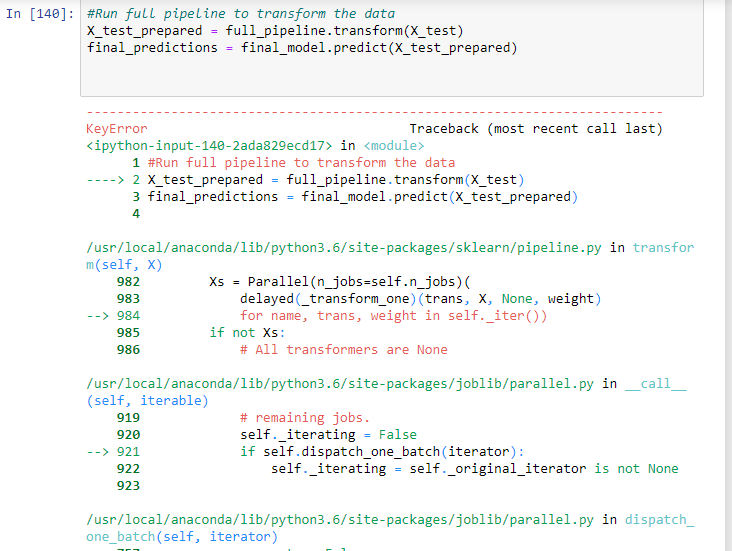
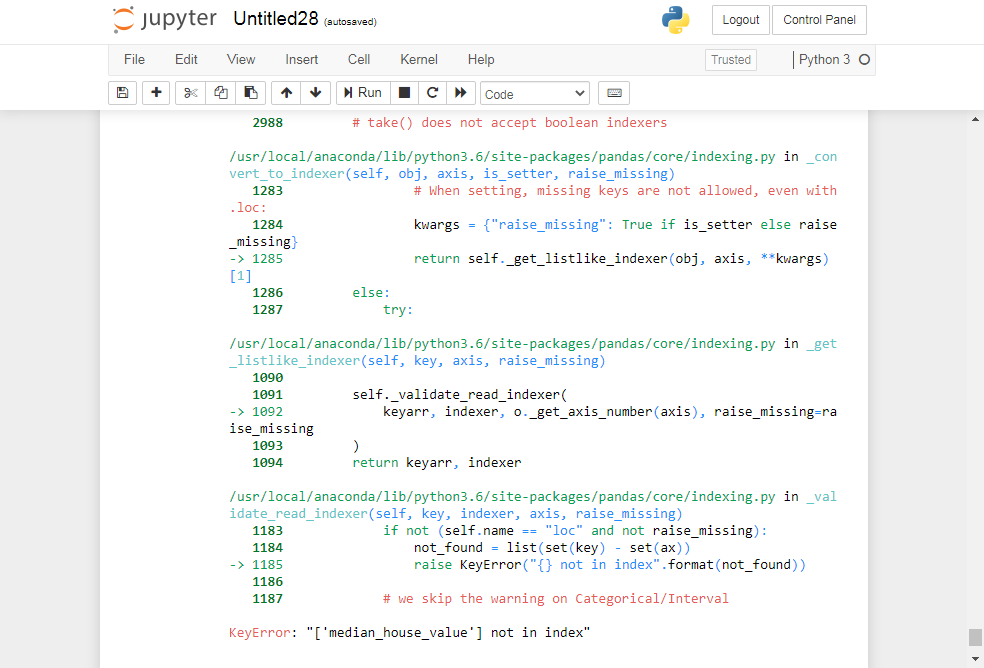
#Run full pipeline to transform the data
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
KeyError Traceback (most recent call last)
in
1 #Run full pipeline to transform the data
----> 2 X_test_prepared = full_pipeline.transform(X_test)
3 final_predictions = final_model.predict(X_test_prepared)
4
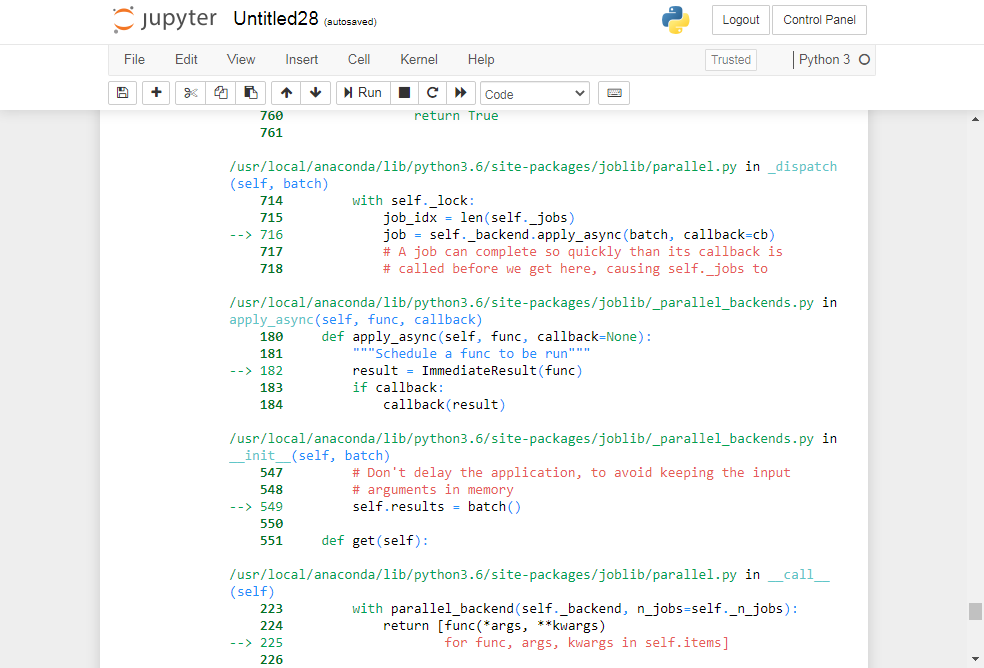
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/pipeline.py in transform(self, X)
982 Xs = Parallel(n_jobs=self.n_jobs)(
983 delayed(_transform_one)(trans, X, None, weight)
–> 984 for name, trans, weight in self._iter())
985 if not Xs:
986 # All transformers are None
/usr/local/anaconda/lib/python3.6/site-packages/joblib/parallel.py in call(self, iterable)
919 # remaining jobs.
920 self._iterating = False
–> 921 if self.dispatch_one_batch(iterator):
922 self._iterating = self._original_iterator is not None
923
/usr/local/anaconda/lib/python3.6/site-packages/joblib/parallel.py in dispatch_one_batch(self, iterator)
757 return False
758 else:
–> 759 self._dispatch(tasks)
760 return True
761
/usr/local/anaconda/lib/python3.6/site-packages/joblib/parallel.py in _dispatch(self, batch)
714 with self._lock:
715 job_idx = len(self._jobs)
–> 716 job = self._backend.apply_async(batch, callback=cb)
717 # A job can complete so quickly than its callback is
718 # called before we get here, causing self._jobs to
/usr/local/anaconda/lib/python3.6/site-packages/joblib/_parallel_backends.py in apply_async(self, func, callback)
180 def apply_async(self, func, callback=None):
181 “”“Schedule a func to be run”""
–> 182 result = ImmediateResult(func)
183 if callback:
184 callback(result)
/usr/local/anaconda/lib/python3.6/site-packages/joblib/_parallel_backends.py in init(self, batch)
547 # Don’t delay the application, to avoid keeping the input
548 # arguments in memory
–> 549 self.results = batch()
550
551 def get(self):
/usr/local/anaconda/lib/python3.6/site-packages/joblib/parallel.py in call(self)
223 with parallel_backend(self._backend, n_jobs=self._n_jobs):
224 return [func(*args, **kwargs)
–> 225 for func, args, kwargs in self.items]
226
227 def len(self):
/usr/local/anaconda/lib/python3.6/site-packages/joblib/parallel.py in (.0)
223 with parallel_backend(self._backend, n_jobs=self._n_jobs):
224 return [func(*args, **kwargs)
–> 225 for func, args, kwargs in self.items]
226
227 def len(self):
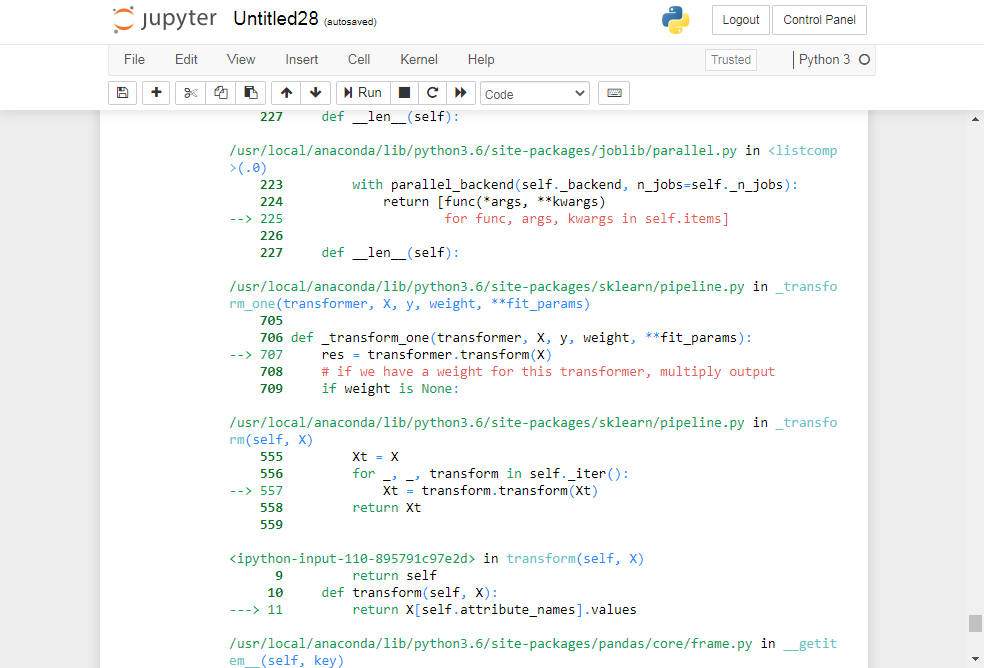
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/pipeline.py in _transform_one(transformer, X, y, weight, **fit_params)
705
706 def _transform_one(transformer, X, y, weight, **fit_params):
–> 707 res = transformer.transform(X)
708 # if we have a weight for this transformer, multiply output
709 if weight is None:
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/pipeline.py in _transform(self, X)
555 Xt = X
556 for _, _, transform in self._iter():
–> 557 Xt = transform.transform(Xt)
558 return Xt
559
in transform(self, X)
9 return self
10 def transform(self, X):
—> 11 return X[self.attribute_names].values
/usr/local/anaconda/lib/python3.6/site-packages/pandas/core/frame.py in getitem(self, key)
2984 if is_iterator(key):
2985 key = list(key)
-> 2986 indexer = self.loc._convert_to_indexer(key, axis=1, raise_missing=True)
2987
2988 # take() does not accept boolean indexers
/usr/local/anaconda/lib/python3.6/site-packages/pandas/core/indexing.py in _convert_to_indexer(self, obj, axis, is_setter, raise_missing)
1283 # When setting, missing keys are not allowed, even with .loc:
1284 kwargs = {“raise_missing”: True if is_setter else raise_missing}
-> 1285 return self._get_listlike_indexer(obj, axis, **kwargs)[1]
1286 else:
1287 try:
/usr/local/anaconda/lib/python3.6/site-packages/pandas/core/indexing.py in _get_listlike_indexer(self, key, axis, raise_missing)
1090
1091 self._validate_read_indexer(
-> 1092 keyarr, indexer, o._get_axis_number(axis), raise_missing=raise_missing
1093 )
1094 return keyarr, indexer
/usr/local/anaconda/lib/python3.6/site-packages/pandas/core/indexing.py in _validate_read_indexer(self, key, indexer, axis, raise_missing)
1183 if not (self.name == “loc” and not raise_missing):
1184 not_found = list(set(key) - set(ax))
-> 1185 raise KeyError("{} not in index".format(not_found))
1186
1187 # we skip the warning on Categorical/Interval
KeyError: “[‘median_house_value’] not in index”
How can i fix this??
Please reply.