

Hi,
On blog, spark version is 2.3 but on ambari it is showing as 2.1.1. On 24th July there has been some update activity on the server. So have you downgraded the version? I am unable to run my application. Please help me on this.
@abhinav, @sandeepgiri
Looks like the Spark version has been downgraded to 2.1.1 from 2.3. Some of my code no longer works and I believe it is due to the version change. Can you please roll it back to 2.3. Current version is almost 2 years old.
Below is the code that no longer works for me.
case class Flight(DEST_COUNTRY_NAME:String,ORIGIN_COUNTRY_NAME:String,count:BigInt)
val flightsDF = spark.read.parquet("file:///home/amalprakash32203955/databricks/Spark-The-Definitive-Guide/data/flight-data/parquet/2010-summary.parquet")
import spark.implicits._
val flightsDS = flightsDF.as[Flight]
def originSameAsDestination(row:Flight):Boolean={
(row.DEST_COUNTRY_NAME).equals(row.ORIGIN_COUNTRY_NAME)
}
flightsDS.filter(row => originSameAsDestination(row)).take(1)
I’m getting the following error
scala> flightsDS.filter(row => originSameAsDestination(row)).take(1)
19/07/28 15:26:53 ERROR Executor: Exception in task 0.0 in stage 5.0 (TID 5)
java.lang.ClassCastException: $line40.$read$$iw$$iw cannot be cast to $line40.$read$$iw$$iw
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:377)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:234)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:228)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:827)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:827)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:99)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)Please use /usr/spark2.3/bin/spark-shell
Looks like it is not configured correctly. Getting the following error now.
2019-07-28 15:59:43 WARN DomainSocketFactory:117 - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
java.lang.NullPointerException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.sql.catalyst.encoders.OuterScopes$$anonfun$getOuterScope$1.apply(OuterScopes.scala:70)
at org.apache.spark.sql.catalyst.expressions.objects.NewInstance$$anonfun$5.apply(objects.scala:348)
at org.apache.spark.sql.catalyst.expressions.objects.NewInstance$$anonfun$5.apply(objects.scala:348)
at scala.Option.map(Option.scala:146)
at org.apache.spark.sql.catalyst.expressions.objects.NewInstance.doGenCode(objects.scala:348)
at org.apache.spark.sql.catalyst.expressions.Expression$$anonfun$genCode$2.apply(Expression.scala:107)
at org.apache.spark.sql.catalyst.expressions.Expression$$anonfun$genCode$2.apply(Expression.scala:104)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.catalyst.expressions.Expression.genCode(Expression.scala:104)
at org.apache.spark.sql.catalyst.expressions.codegen.GenerateSafeProjection$$anonfun$3.apply(GenerateSafeProjection.scala:148)
at org.apache.spark.sql.catalyst.expressions.codegen.GenerateSafeProjection$$anonfun$3.apply(GenerateSafeProjection.scala:145)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.immutable.List.foreach(List.scala:381)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.immutable.List.map(List.scala:285)
at org.apache.spark.sql.catalyst.expressions.codegen.GenerateSafeProjection$.create(GenerateSafeProjection.scala:145)
at org.apache.spark.sql.catalyst.expressions.codegen.GenerateSafeProjection$.create(GenerateSafeProjection.scala:36)
at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator.generate(CodeGenerator.scala:1321)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3277)
at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2489)
at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2489)
at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3259)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3258)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2489)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2703)
... 48 elidedMy parquet file was corrupted by the data migration. It was restored and I’m good now. Thank you.
scala> flightsDS.show(2)
2019-07-28 17:32:41 WARN CorruptStatistics:112 - Ignoring statistics because created_by could not be parsed (see PARQUET-251): parquet-mr (build 32c46643845ea8a705c35d4ec8fc654cc8ff81
6d)
org.apache.parquet.VersionParser$VersionParseException: Could not parse created_by: parquet-mr (build 32c46643845ea8a705c35d4ec8fc654cc8ff816d) using format: (.*?)\s+version\s*(?:([^(]
*?)\s*(?:\(\s*build\s*([^)]*?)\s*\))?)?
at org.apache.parquet.VersionParser.parse(VersionParser.java:112)
at org.apache.parquet.CorruptStatistics.shouldIgnoreStatistics(CorruptStatistics.java:67)
at org.apache.parquet.format.converter.ParquetMetadataConverter.fromParquetStatisticsInternal(ParquetMetadataConverter.java:348)
at org.apache.parquet.format.converter.ParquetMetadataConverter.fromParquetStatistics(ParquetMetadataConverter.java:365)
1 Like

I tried to run my application on 2.1.1 as well as 2.3.3. In both the case it is failing.
In 2.1.1, few functions I have used which are not there. In 2.3.3, some classNotfound exception is coming.
About my application: It was initially created in spark 2.3.0 with scala 2.11.12. It is spark structured streaming application which is reading data from kafka and writing to HDFS. The application was working fine with earlier setting of cloudera i.e spark 2.3.0. But now it is not working.
Please help
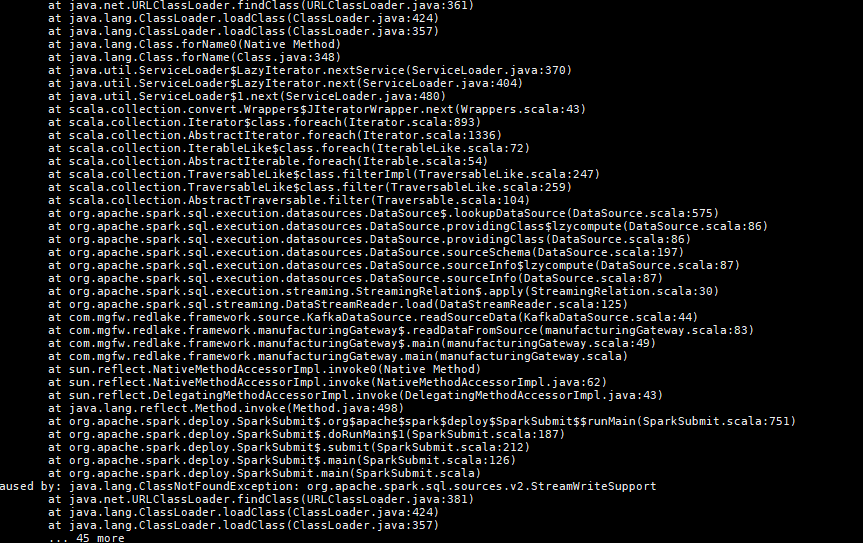
@BIGDATACLOUDSOLUTION
Try setting spark.hadoop.yarn.timeline-service.enabled to false
When launching spark shell, do something like
/usr/spark2.3/bin/spark-shell --conf spark.hadoop.yarn.timeline-service.enabled=false
When I am using
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master
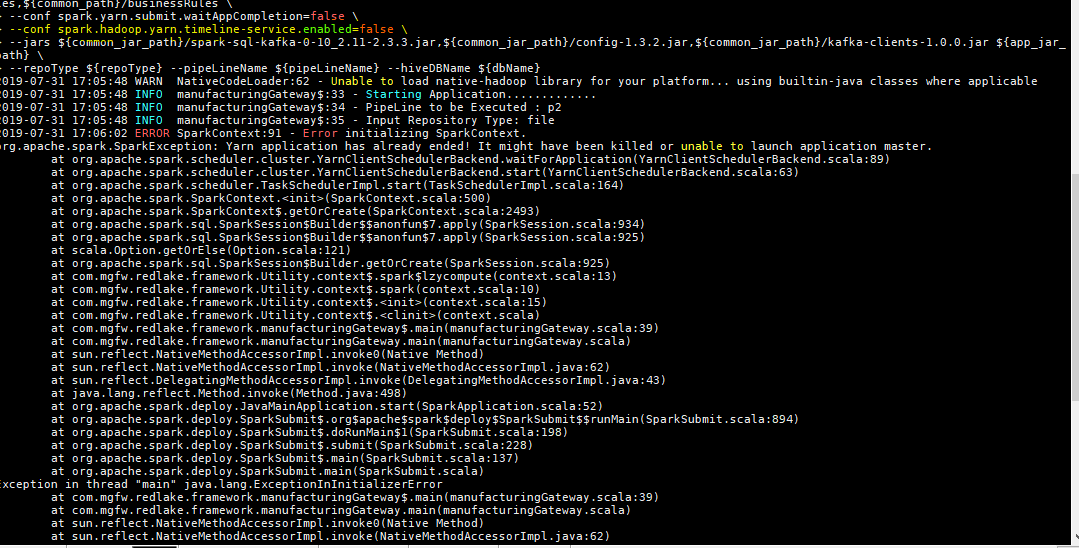
conf spark.hadoop.yarn.timeline-service.enabled=false, I am getting another exception:org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master
I don’t understand why you guys don’t revert back the spark version?
Please resolve the issue asap.
Please resolve the issue. I am waiting for your(cloudxlab team) update.