
I am writing a simple program in spark to write to hive from jupyter notebook. But I am not able to see the records inserted. Can someone pls let me know what is wrong?
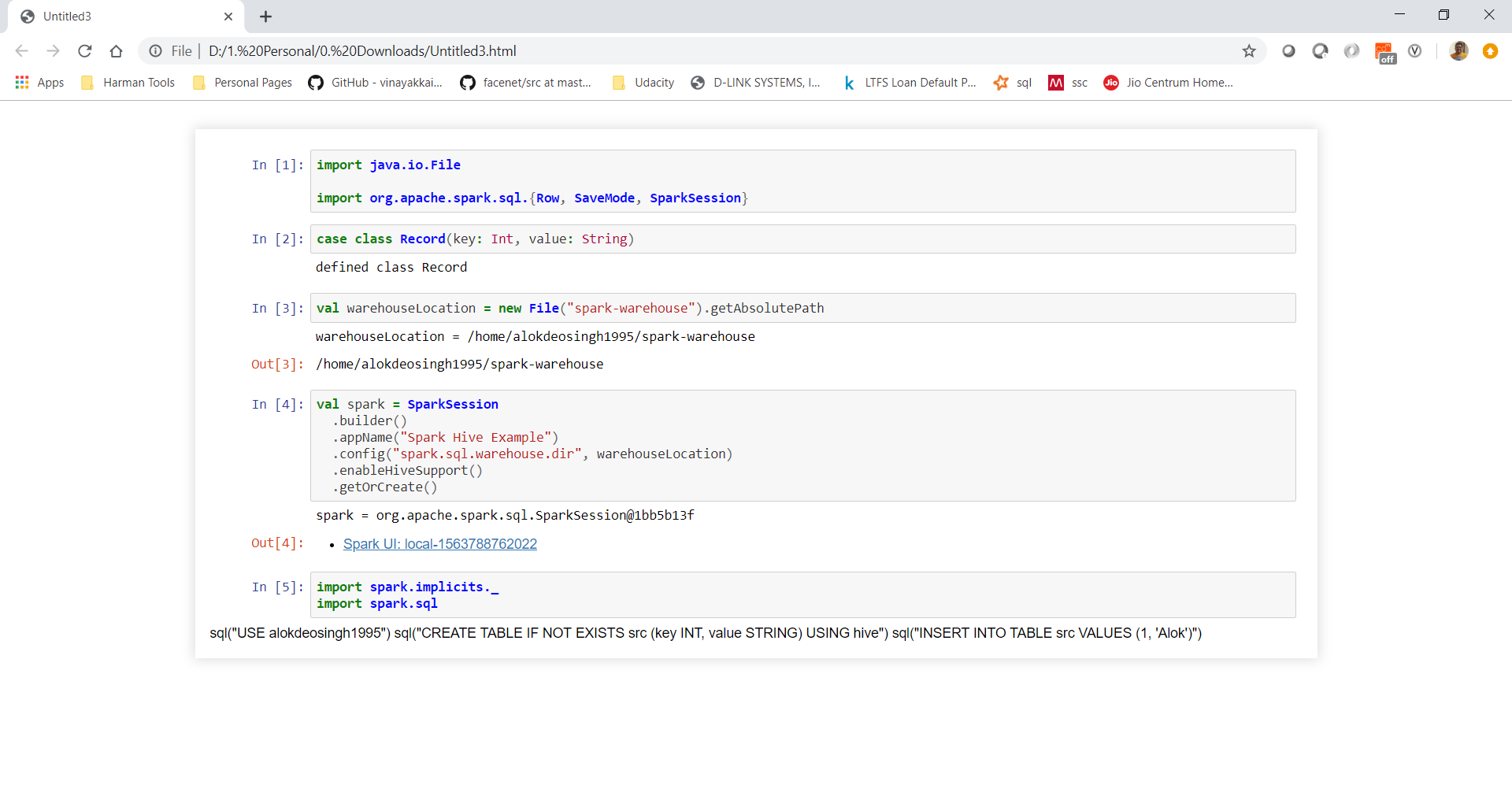
Actually, this would try to write in /home/alokdeosingh1995 folder in HDFS and in HDFS /home does not exist.
I would suggest that in .config, you should simply pass a string like this:
.config("spark.sql.warehouse.dir", "spark-warehouse")
Thanks Sandeep for the quick reply! I tried it and it worked. However, when I add some kafka jars to read kafka in my spark program, it does not find the db again.
%AddJar http://central.maven.org/maven2/org/apache/spark/spark-streaming-kafka-0-10-assembly_2.11/2.4.3/spark-streaming-kafka-0-10-assembly_2.11-2.4.3.jar
%AddJar http://central.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.11/2.0.2/spark-sql-kafka-0-10_2.11-2.0.2.jar
Code that works and writes to hive:
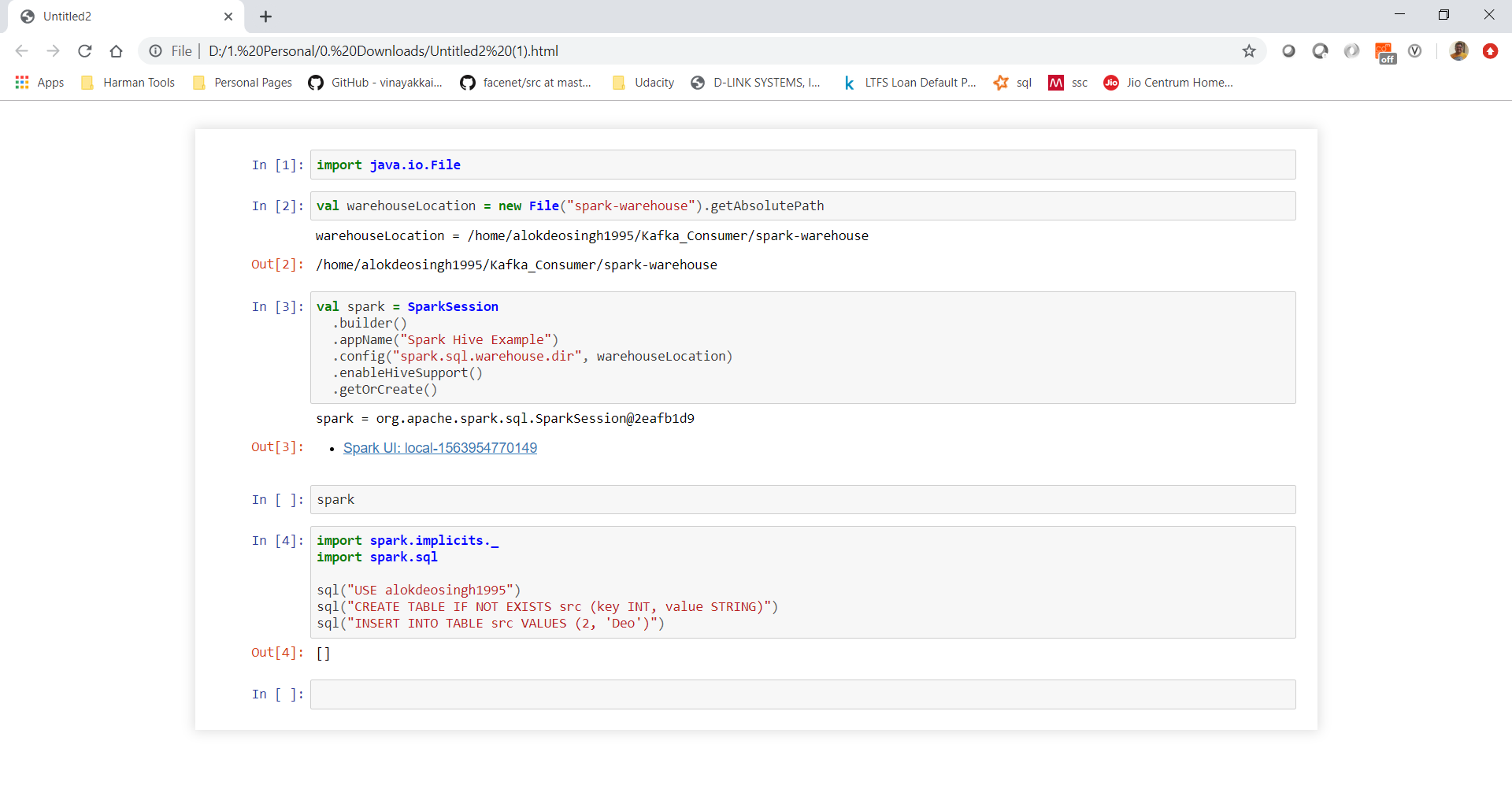
Code that does not works and gives error when writing to hive.
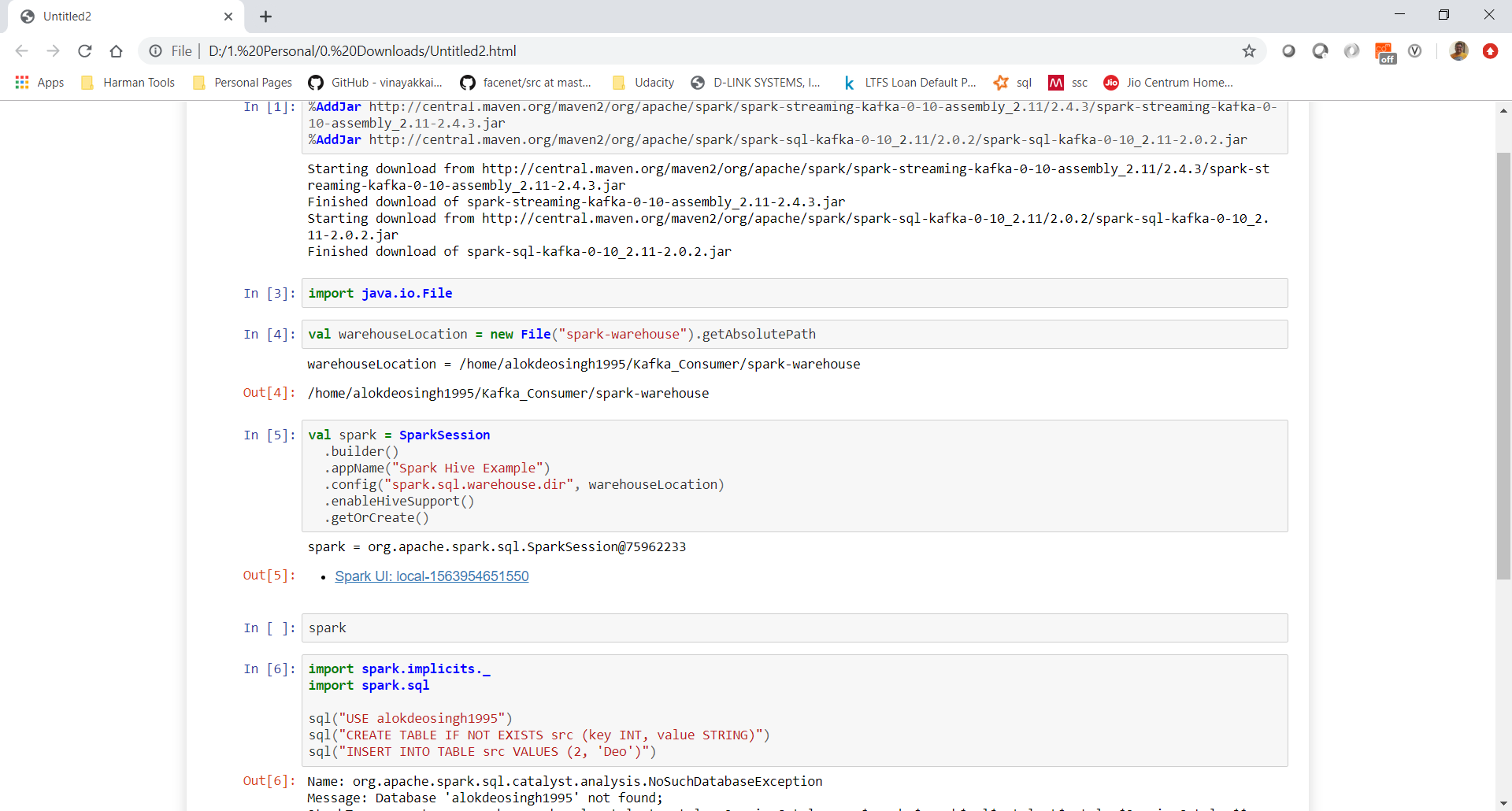
Are the jars being added to different spark handle which jupyter starts?
Hi,
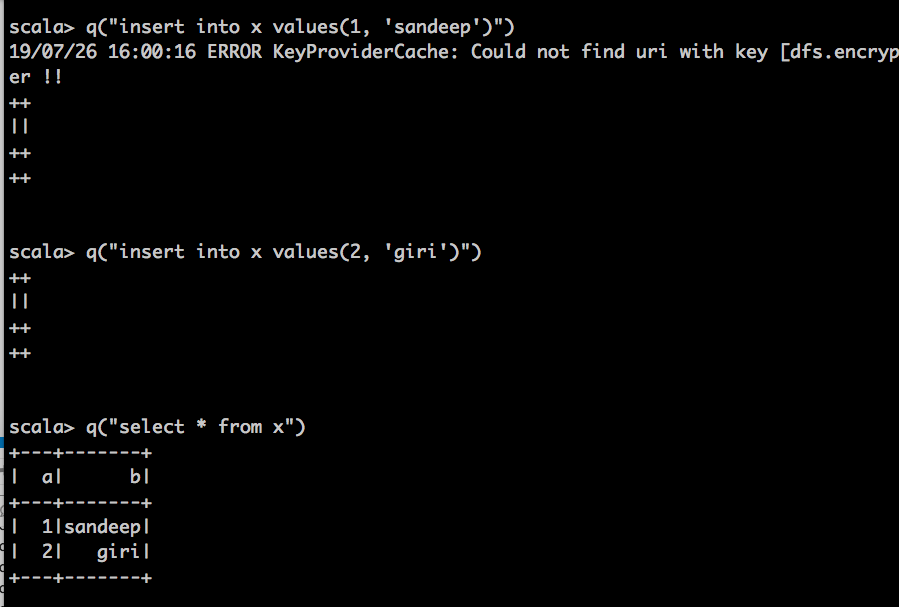
the new spark was not setting the hive warehouse directory correctly. So, I have fixed it. You don’t need to set the lcoation. I tried the following it worked well on spark-shell:
def q(s:String) = spark.sql(s).show()
q(“create database sg”)
q(“show tables”)
q(“create table x(a int, b varchar(10))”)
q(“show tables”)
q(“insert into x values(1, ‘sandeep’)”)
q(“insert into x values(2, ‘giri’)”)
q(“select * from x”)
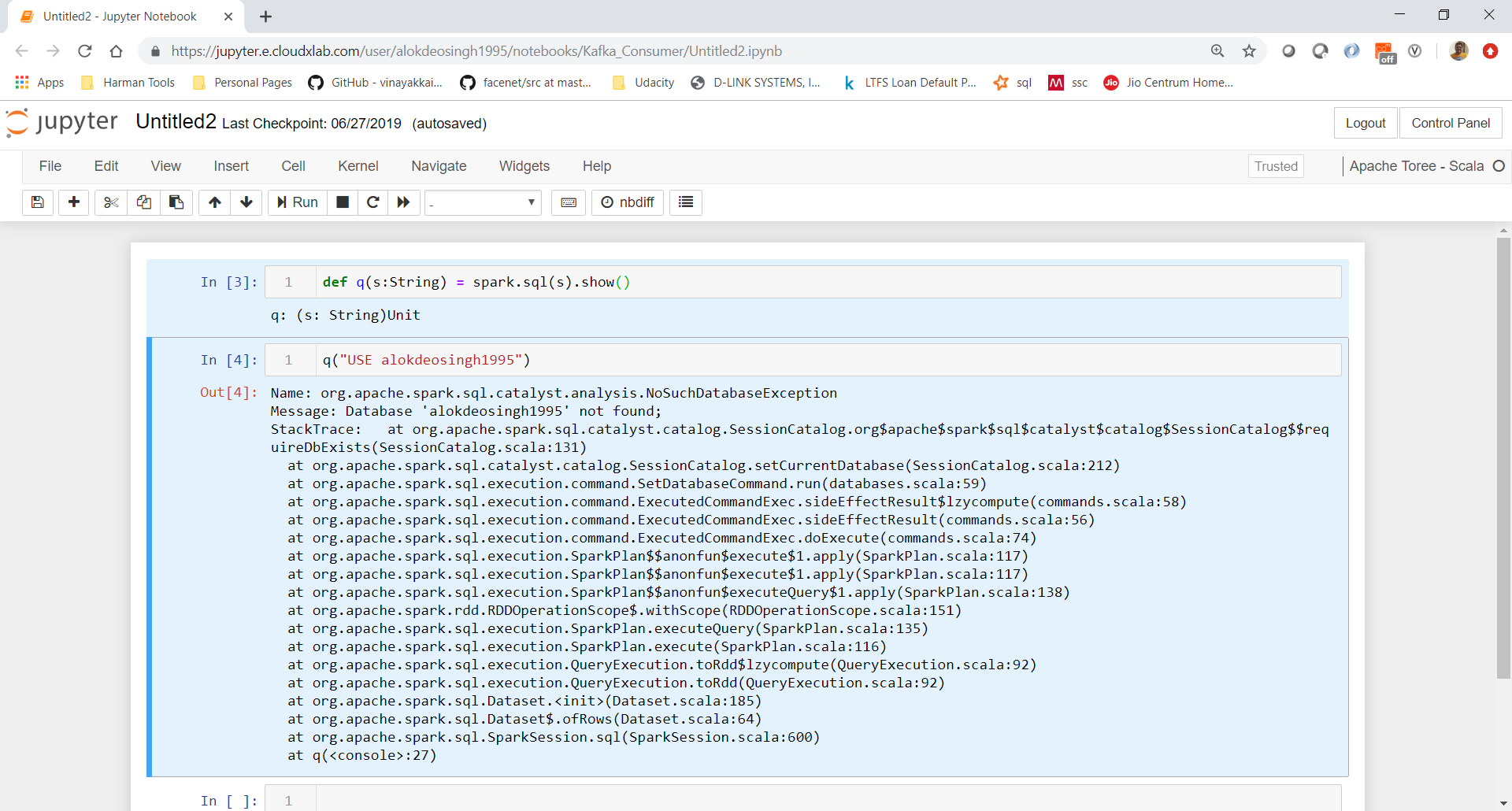
Also noticed that this does not work in cluster mode.
spark-submit --class com.alok.projects.entry --master yarn --deploy-mode cluster target/scala-2.11/kafkaconsumer_2.11-0.1.jar
But works in local mode
spark-submit --class com.alok.projects.entry --master local[*] kafkaconsumer_2.11-0.1.jar
There is something wrong that I am doing, can you please point it to me. Thanks!
Thanks Sandeep! I got the answer. The reply on this SO post https://stackoverflow.com/questions/34034488/hive-tables-not-found-when-running-in-yarn-cluster-mode
worked!
spark-submit --class com.alok.projects.entry --master yarn --deploy-mode cluster --files /usr/hdp/current/spark-client/conf/hive-site.xml kafka
consumer_2.11-0.1.jar
But this still doesnot works on jupyter. How to set files parameter there?