
Hi,
When I am trying
sc=StandardScaler()
X_train=sc.fit_transform(X_train)
X_test=sc.transform(X_test)
I get a value error.
Can’t we do feature scaling this way.
for reference, see code below.
Since we cannot view either the dataset, or the error message here, let me assume there are categorical variables in this dataset. Have you accounted for them before applying StandardScaler? Also, it would be helpful if you could show the actual error message.
Hi Rajtilak!
please find the link to code and data set below.
1.https://drive.google.com/file/d/1ucE7FopHquK9j19qnYBNe5CoUtAp6Aw5/view?usp=sharing
2.https://drive.google.com/file/d/1NSZMwLK9hRPNJAKpbmioSsDuAoP_v1dL/view?usp=sharing
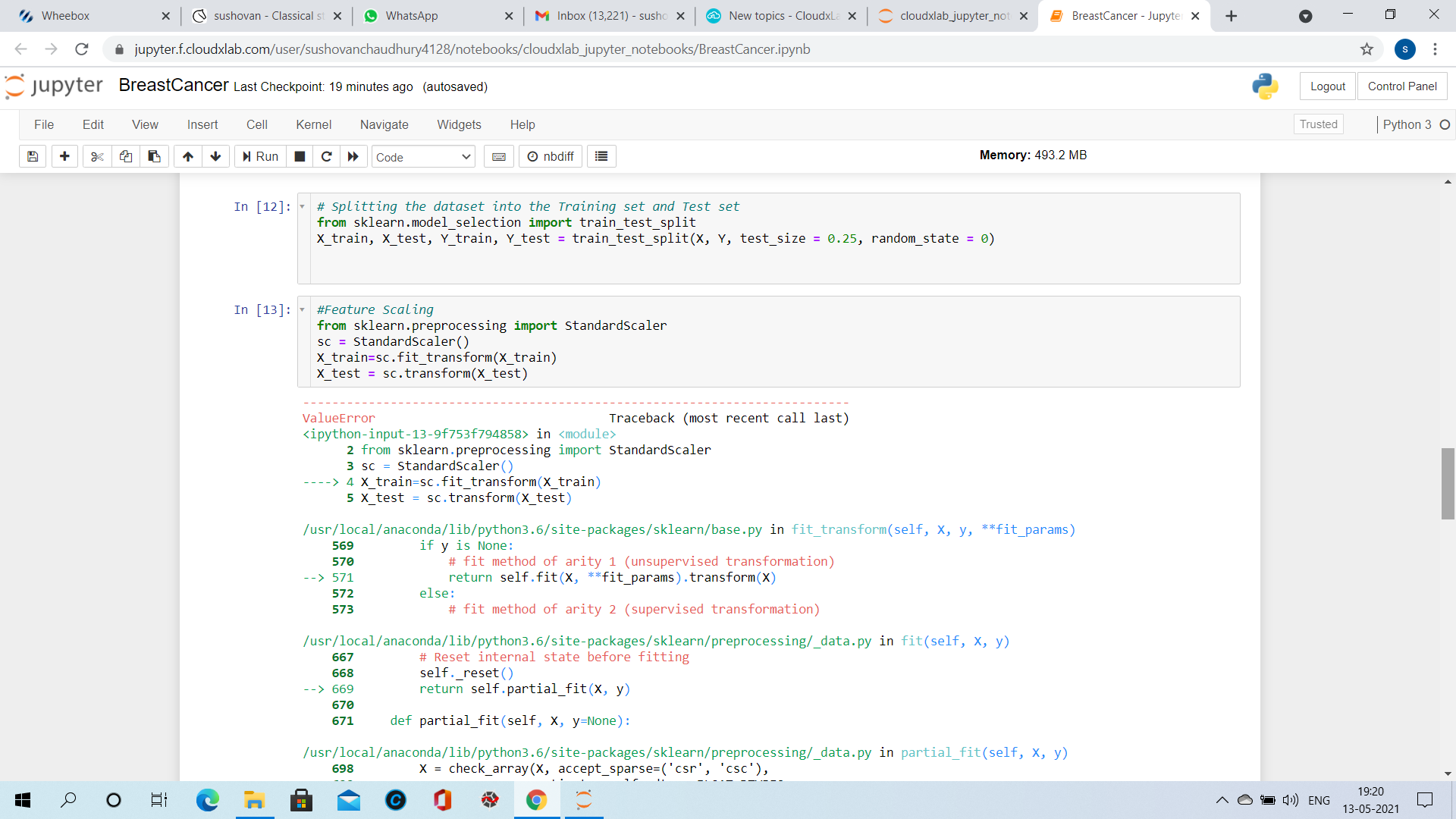
The complete error message is below:
ValueError Traceback (most recent call last)
in
2 from sklearn.preprocessing import StandardScaler
3 sc = StandardScaler()
----> 4 X_train=sc.fit_transform(X_train)
5 X_test = sc.transform(X_test)
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/base.py in fit_transform(self, X, y, **fit_params)
569 if y is None:
570 # fit method of arity 1 (unsupervised transformation)
–> 571 return self.fit(X, **fit_params).transform(X)
572 else:
573 # fit method of arity 2 (supervised transformation)
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/preprocessing/_data.py in fit(self, X, y)
667 # Reset internal state before fitting
668 self._reset()
–> 669 return self.partial_fit(X, y)
670
671 def partial_fit(self, X, y=None):
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/preprocessing/_data.py in partial_fit(self, X, y)
698 X = check_array(X, accept_sparse=(‘csr’, ‘csc’),
699 estimator=self, dtype=FLOAT_DTYPES,
–> 700 force_all_finite=‘allow-nan’)
701
702 # Even in the case of with_mean=False, we update the mean anyway
/usr/local/anaconda/lib/python3.6/site-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, warn_on_dtype, estimator)
529 array = array.astype(dtype, casting=“unsafe”, copy=False)
530 else:
–> 531 array = np.asarray(array, order=order, dtype=dtype)
532 except ComplexWarning:
533 raise ValueError(“Complex data not supported\n”
/usr/local/anaconda/lib/python3.6/site-packages/numpy/core/numeric.py in asarray(a, dtype, order)
536
537 “”"
–> 538 return array(a, dtype, copy=False, order=order)
539
540
ValueError: could not convert string to float: ‘B’
I believe here the issue is that you are trying to convert a string into float that is not a valid float number. Please check if these string are actual strings and if you need to encode them before applying StandardScaler on them. You will find the below link helpful:
I have solved it.Thank you.
how do you solve it???