
Hi Cloud X Team / Rajthilak,
Need clarification regarding some steps:
Want to know which one is appropriate? & Why so???
a) After Train-Test Split, Scaling of Response /Independent variables is done as shown below:
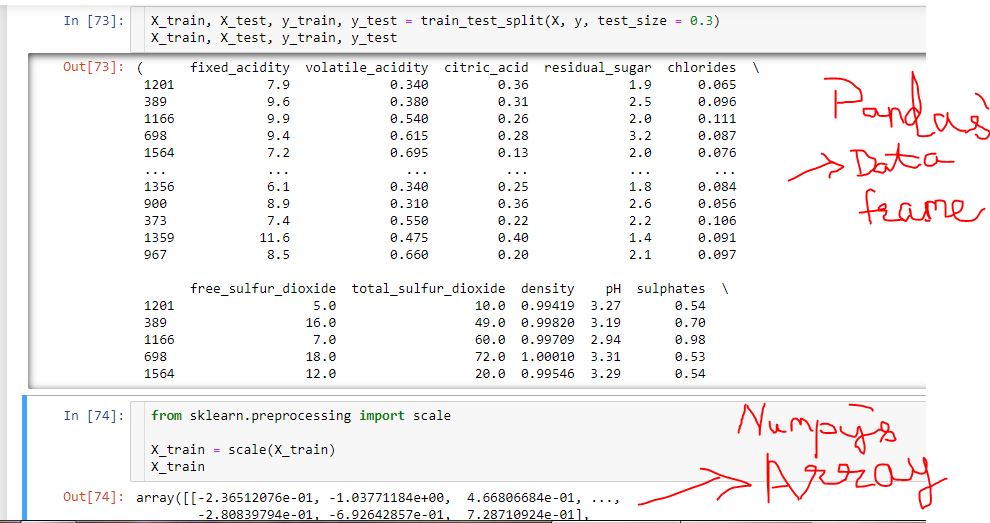
But in the aforesaid/above screenshot , a Numpy Dataframe is getting converted to a Numpy Array by invoking Scaling.
b) In the given screenshot, Scaling is done before Train-Test Split as follows—
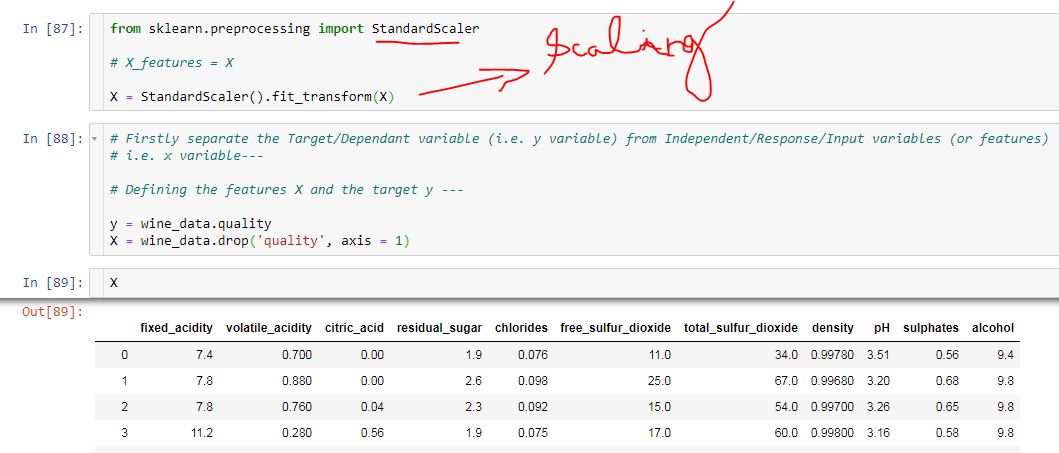
But as seen in the aforesaid case, there is no effect of Scaling seen in dataset X (i.e. Independent Variables).
c) Again this is similar to point a as stated above. Scaling is done after the Splitting of Train-Test Set.
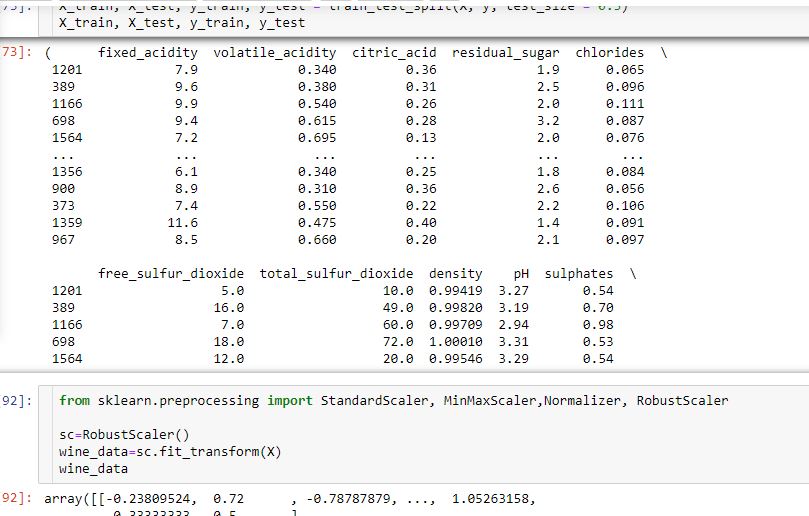
But again the dataset which is imported as a Dataframe is getting converted into a Array.
Following are my doubts:
a) Is there a mistake in my codes? What are the mistakes/errors committed by me?
b) Why is a Pandas Dataframe getting converted into a Numpy Array?
c) While doing a Project, should one initiate Scaling before the Train-Test Split or should one do Scaling after the Train-Test Split?
Hope I do get a reply and doubts resolved for this ASAP—as I don’t get much time to spare during the weekdays as I’m a working professional.