Just curious to know any one tried to schedule PySpark Module in Oozie.
What are the fields that I need to enter here for the bellow . These fields are required for Spark Action in Oozie.
- Spark Master
- Mode
- Main class
- Jars/py files

Just curious to know any one tried to schedule PySpark Module in Oozie.
What are the fields that I need to enter here for the bellow . These fields are required for Spark Action in Oozie.
I have not yet tried in Oozie but here is my guess.
Please note that these arguments are very similar to spark-submit arguments.
See more at https://spark.apache.org/docs/latest/submitting-applications.html
or in the Running on Cluster section of our course: https://cloudxlab.com/course/specialization/3/
This just worked perfectly fine:
master: local[*]
Mode: client
AppName: Anything
Main: org.apache.spark.examples.SparkPi
jars: /usr/hdp/current/spark-client/lib/spark-examples-1.5.2.2.3.4.0-3485-hadoop2.7.1.2.3.4.0-3485.jar
arguments: 10
I just created a 10min video. Here is the video of Spark running on Oozie:
Thanks for this. This is for Java/Scala with Spark right …
But when we are submitting PySpark What should I fill on Main Class fields
I created a pySpark Job and its working perfectly fine on submitting thru spark-submit. Now When I tried thru Oozie its failing. I doubt the Fields that the fields I enter has issues . These fields are required for Spark Action in Oozie.
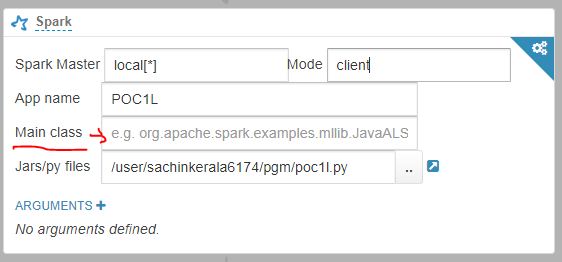
Can you share your files?