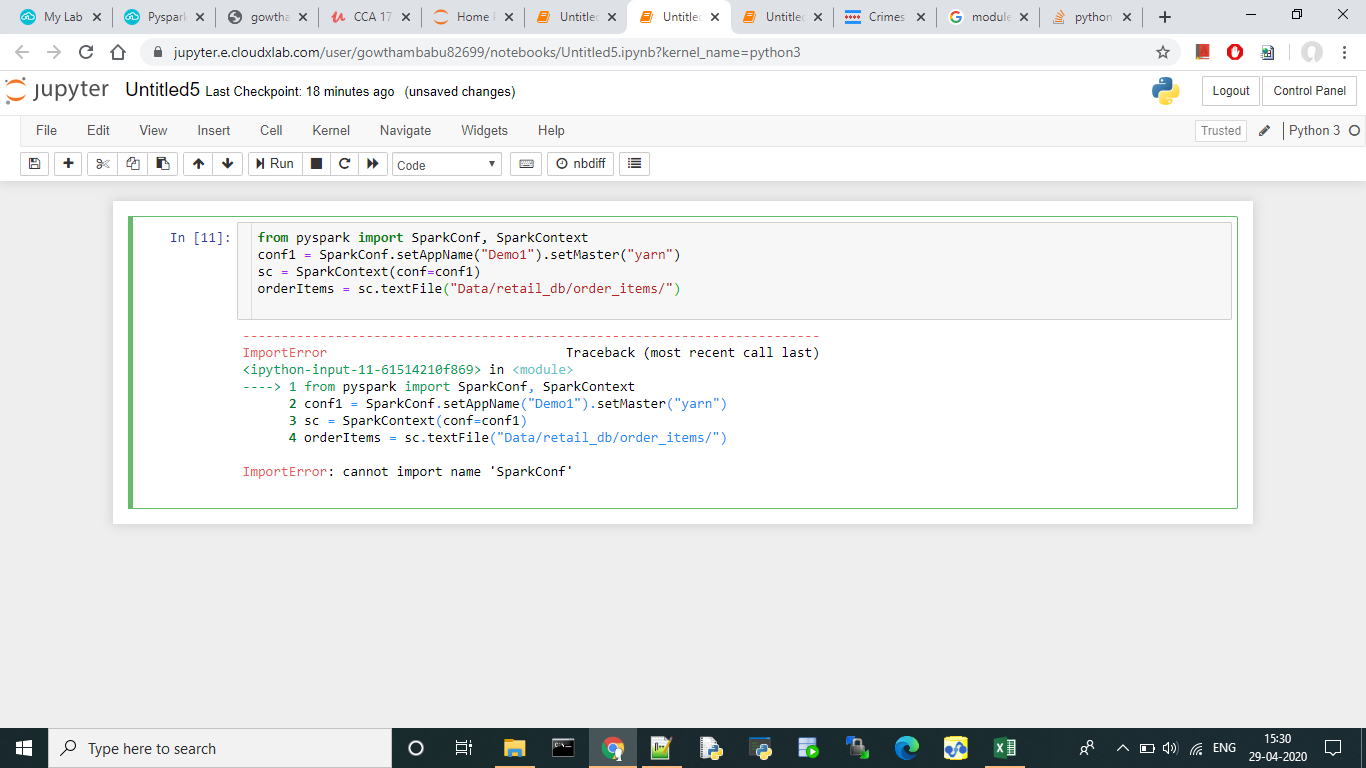
Please see how to get started here:
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import sys"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Specify spark 2.2 version"
]
},
{
show original
The other tutorials on Spark with Python are here:
If you are learning pyspark i.e. Spark using Python, please note that the API is almost same as Scala.
Here are the links to the code:
## Spark with Python
https://github.com/cloudxlab/bigdata/tree/master/spark/python
https://github.com/cloudxlab/bigdata/tree/master/spark/examples/python
## GraphX
https://github.com/cloudxlab/bigdata/blob/master/spark/examples/graphx/pagerank.py.md
## Mllib
https://github.com/cloudxlab/bigdata/blob/master/spark/examples/mllib/mllib_random_forrest.ipynb
https://github.com/cloudxlab/bigdata/blob/master/spark/examples/mllib/movie-recommendations.py
## Streaming with Pyspark
https://github.com/cloudxlab/bigdata/blob/master/spark/examples/streaming/word_count/word_count.py
## Streaming with Pyspark and Kafka
https://github.com/cloudxlab/bigdata/blob/master/spark/examples/streaming/word_count_kafka/word_count_kafka_spark_streaming.md
show original