I am getting “java.lang.OutOfMemoryError: Java heap space” error while running ml-recommender.scala ( .reduce(_ + _) ) program.
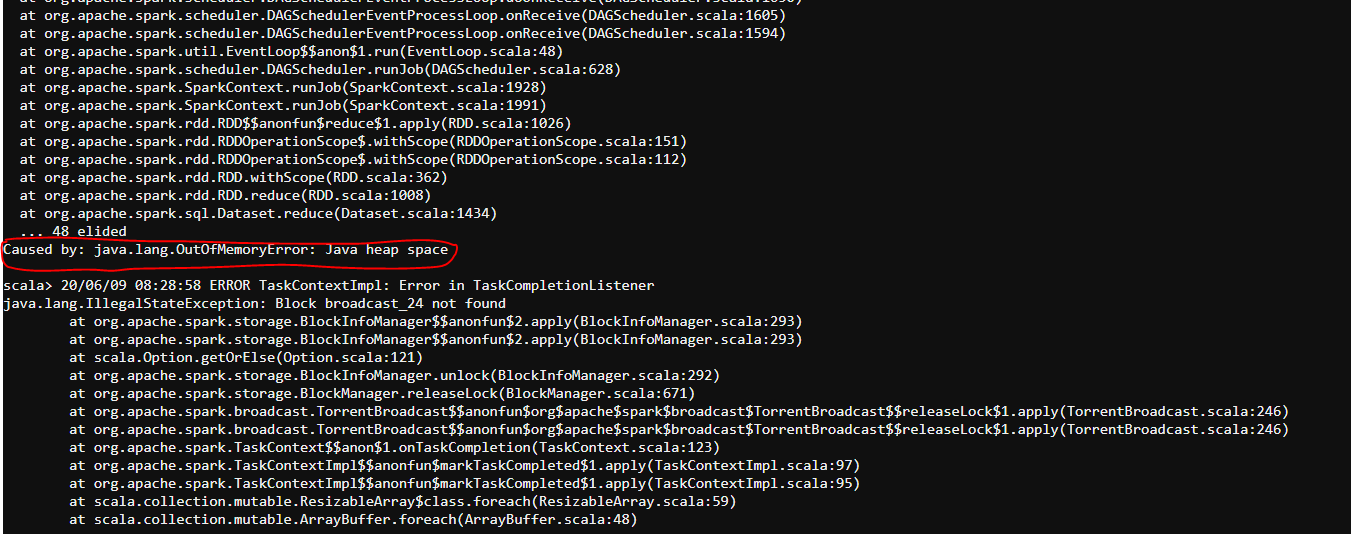
Could you please help me to resolve it.

I am getting “java.lang.OutOfMemoryError: Java heap space” error while running ml-recommender.scala ( .reduce(_ + _) ) program.
Could you please help me to resolve it.
Hi, Akshita.
There is a possibility that the recommendations program in scala is taking more space that is allocated to you and that is why you are getting Heap/memory leak issue.
I recommend you to delete some unwanted file and try to rerun it.
Also kindly refer to the Fair-Policy usages for better insights. :-
https://cloudxlab.com/faq/6/what-are-the-limits-on-the-usage-of-lab-or-what-is-the-fair-usage-policy-fup#:~:text=What%20are%20the%20limits%20on%20the%20usage%20of%20lab%20or,for%20educational%20and%20PoC%20purposes.&text=Here%20are%20the%20limits%20as,the%20replication%20factor%20of%203.
All thw best!
Hi Satyajit,
I don’t have any unwanted or big file in my HDFS and even though set the replication factor as 1, please check and let me know if you need additional information.
Hi, Akshita.
The below code is a computationally intensive task, because it is doing the matrix factorizations on the entire dataset.
//Alternating Least Squares (ALS) matrix factorization.
val als = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol(“userId”).setItemCol(“movieId”).setRatingCol(“rating”)
in .transform it internally do the operations such as
These are highly resource intensive and it will leads to overflow of the memory(basically Heap memory) and not HDFS space if not sufficiently assigned.
Or it happens when in the configurations the specified java heap size is insufficient for the application or task to run.
Learners have been assigned 2GB of the RAM and a fixed Heap memory.
I recommend you to run the code in your local system and to the best of my knowledge and it should be fine.
To see the working of the project you can watch the 2:18:34 timestamp of the video.

Hi Satyajit,
Thanks for sharing the video.
I am getting disk space exceeded error while trying to save "“model.save(“mymodel”)” file in HDFS.
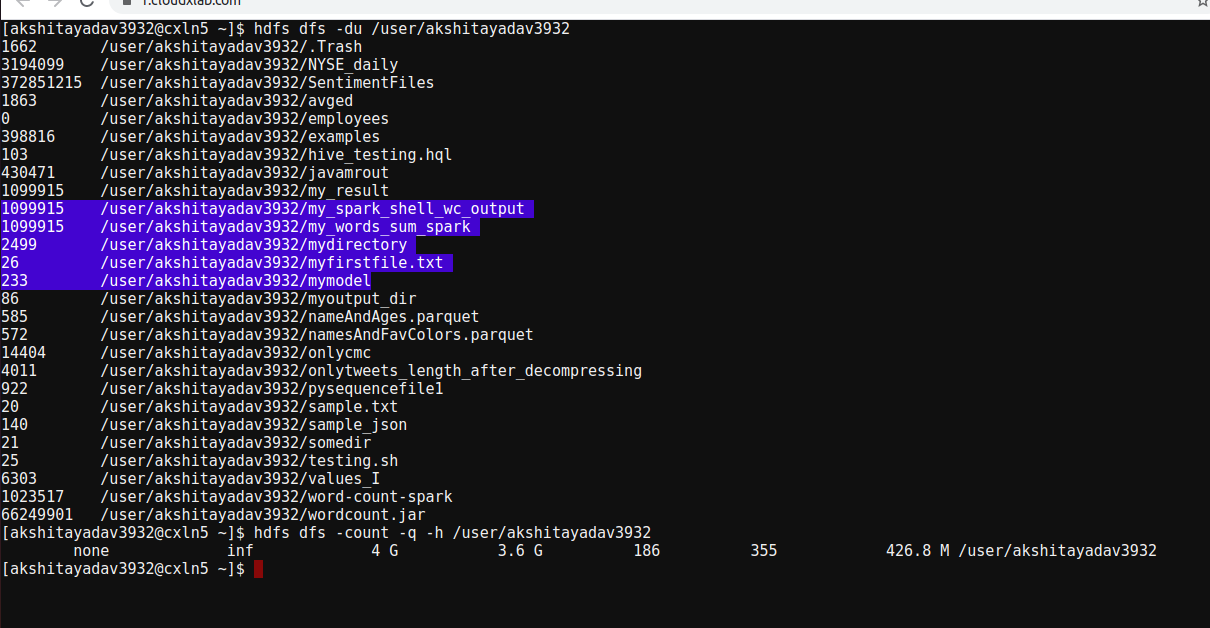
My files consumed 400 MB HDFS space only.
Could you please help me to fix it.
Hi, Akshita.
I completely agree with you.
I have checked your space used and you have still have 3.6GB free out of 4GB allocated.
But when you are running this recommendation programs in spark -shell, then as I observed you are getting a 200MB model file in your case and now as the default replication factor is 3 so you need 600MB file or .6 GB. and as we know that the disk space quota is deducted based not only on the size of the file you want to store in HDFS but also the number of replicas and replication factor.
Similarly you have many files and they all will be required or have consumed the thrice of their size and as you told you set the replication factor for 1 it may be for i file but other file have by default replications factor of 3.
Now, what I recommend is try deleting all the files files from your HDFS as you have already completed all the Hive etc so not needed, and try out the recommender program one more time.
I hope this time it should work, otherwise I recommend to run in the local system.
All the best!
Hi Satyajit
I have removed some files from HDFS still getting the same error.
I tried with small file but not able to save this file in HDFS.
(var rdd = sc.parallelize(Array((“key1”,1.0),(“key2”,2.0),(“key3”,3.0)))
rdd.saveAsSequenceFile(“pysequencefile1”)).
Hi, Akshita.
I am doing the breadth and depth wise search on this and once I find the cause and resolve it. I will let you know.
Recently, the partitions created by every file has been increased.
Kindly refer to this discussions for more information :-
Thanks for your understanding and any of your suggestions on this will be appreciated.
Thank you for the detailed explanation of the reason for ‘out of memory’ usage. I am studying the topic of machine learning. and got this error when I apply the Alternating Least Squares (ALS) matrix factorization. based on this feedback, i changed the code slightly in 2 locations
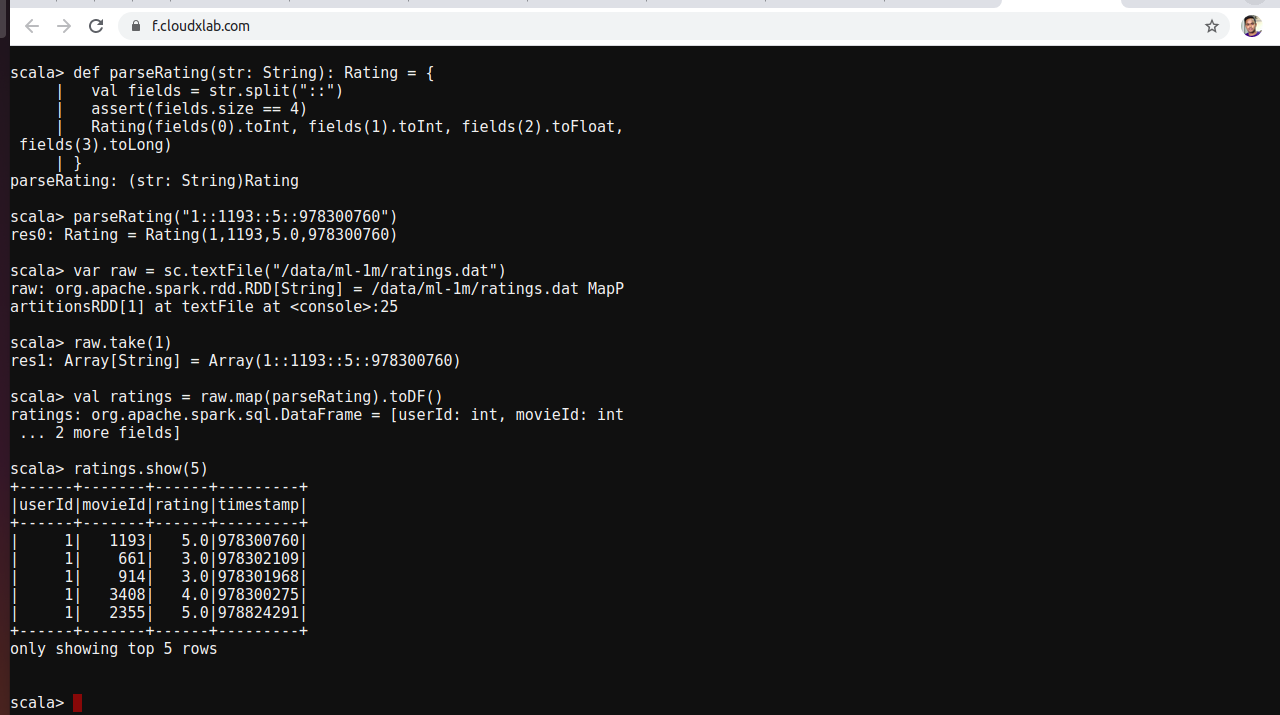
var raw = sc.textFile("/data/ml-1m/ratings.dat",1) and val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2),1)
please see my comments - I get the same error
//code starts here
import org.apache.spark.ml.recommendation.ALS
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
//Test it
parseRating(“1::1193::5::978300760”)
var raw = sc.textFile("/data/ml-1m/ratings.dat",1) //modified
//check one record. it should be res4: Array[String] = Array(1::1193::5::978300760)
//If this fails the location of file is wrong.
raw.take(1)
val ratings = raw.map(parseRating).toDF()
//check if everything is ok
ratings.show(5)
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2),1) //modified
training.show(1)
test.show(1)
//no issues till here
// Build the recommendation model using ALS on the training data
//Alternating Least Squares (ALS) matrix factorization.
val als = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol(“userId”).setItemCol(“movieId”).setRatingCol(“rating”)
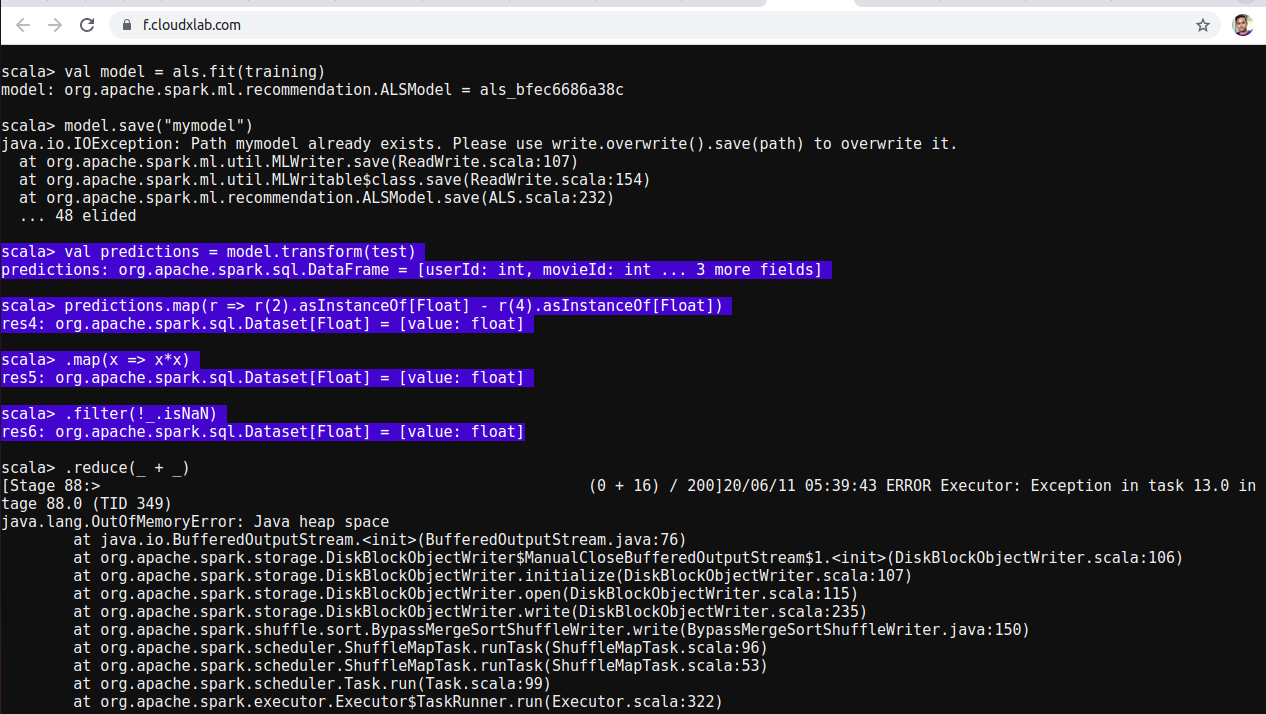
val model = als.fit(training)
model.save(“mymodel”)
//Prepare the recommendations
val predictions = model.transform(test)
predictions.show(1)
//java.lang.OutOfMemoryError: Java heap space. same as before
In general, OutOfMemoryError occurs because the JVM doesn’t have enough heap space to process such a large dataset. Similarly here, the error “java.lang.OutOfMemoryError: Java heap space” seems to occur when the JVM runs out of memory while executing the ml-recommender.scala program. During operations like the .reduce(_ + _) system will require loading large volumes of data into memory. In such cases, you can try to overcome this issue by increasing the JVM heap size. You can increase it by introducing or making changes to -Xms and -Xmx as per your workload needs and increase the memory to the program. In addition, it is important to ensure that data is processed efficiently, possibly in smaller partitions, processing no unnecessary objects are retained memory. Rather than loading everything into memory at once, process data in chunks can actually help with your memory utilization. Check if you are using memory efficient data structures. This will help in preventing heap exhaustion and allow the program to complete successfully without running into out-of-memory errors.