
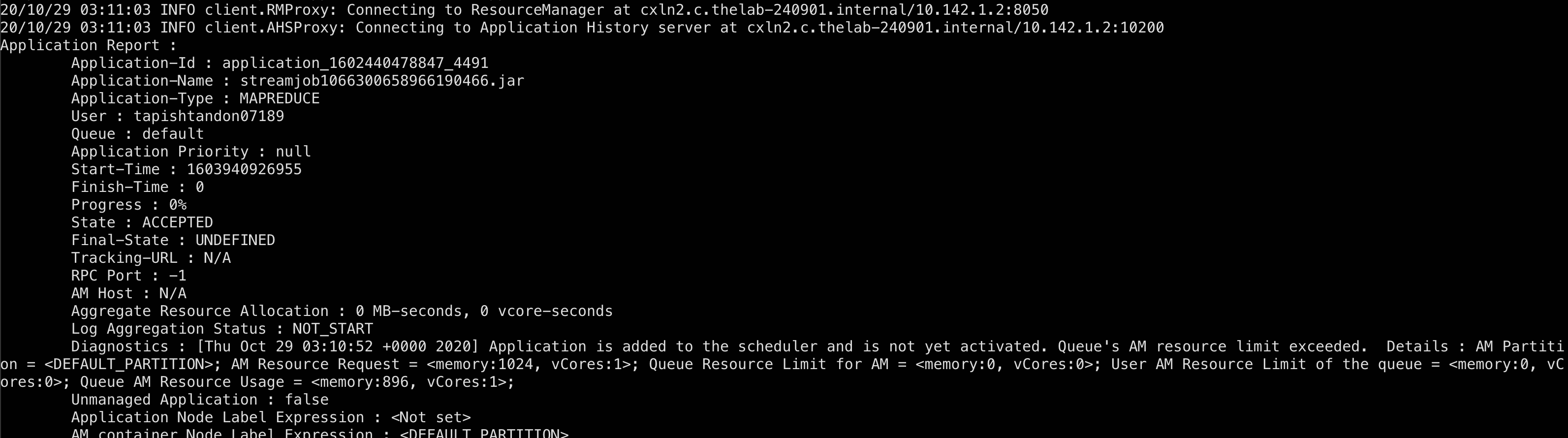
The job is stuck and progress is constant around 0%. Can you please help me understand where exactly is the problem?
Hi, @Tapish_Tandon
The basics error you are getting is “The AM Master resource limit have been exceeded”.
When you submit the jobs then it will be stored in the Queue, as you know that every Queue has some space constraints and limits.
So, here the clusters resources allocated to the The Application Master (AM) seems to be filled.
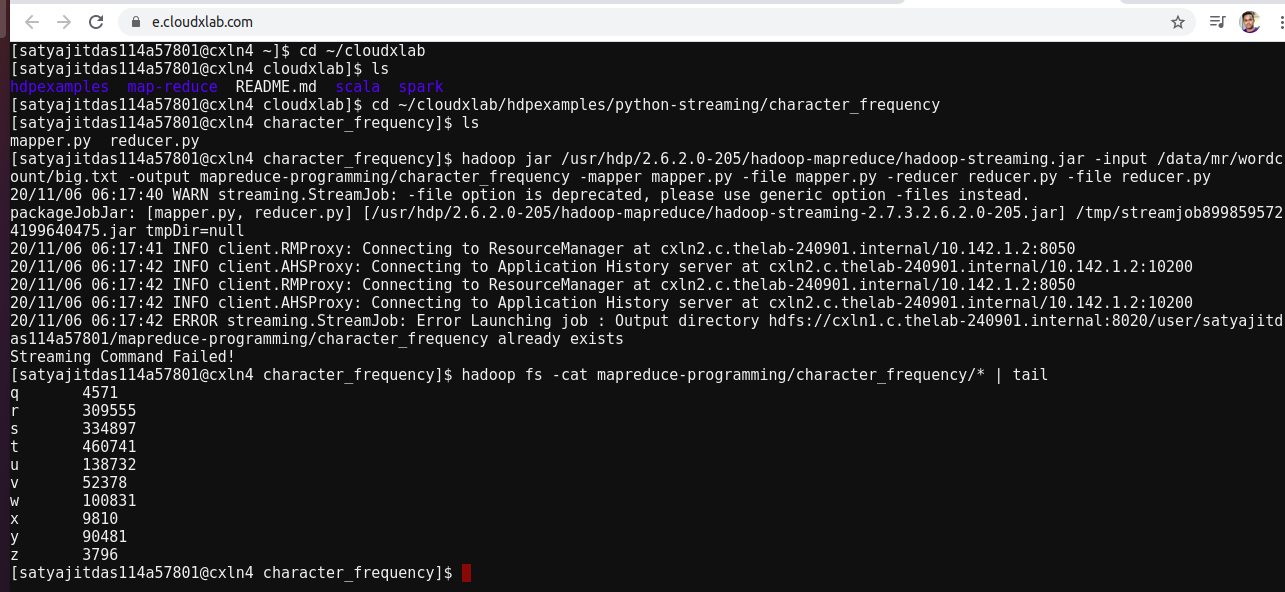
You need to go to the below directory.
cd ~/cloudxlab/hdpexamples/python-streaming/character_frequency
because you have the mapper and reducer file over there.
- and run the below command.
hadoop jar /usr/hdp/2.6.2.0-205/hadoop-mapreduce/hadoop-streaming.jar -input /data/mr/wordc
ount/big.txt -output mapreduce-programming/character_frequency -mapper mapper.py -file mapper.py -reducer reducer.py -file reducer.py
I just run and it worked for me.
All the best!