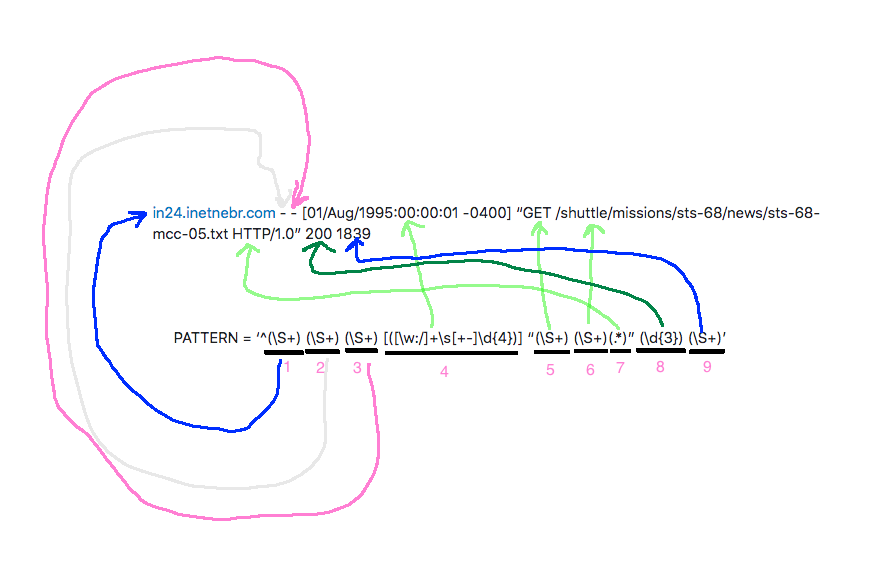
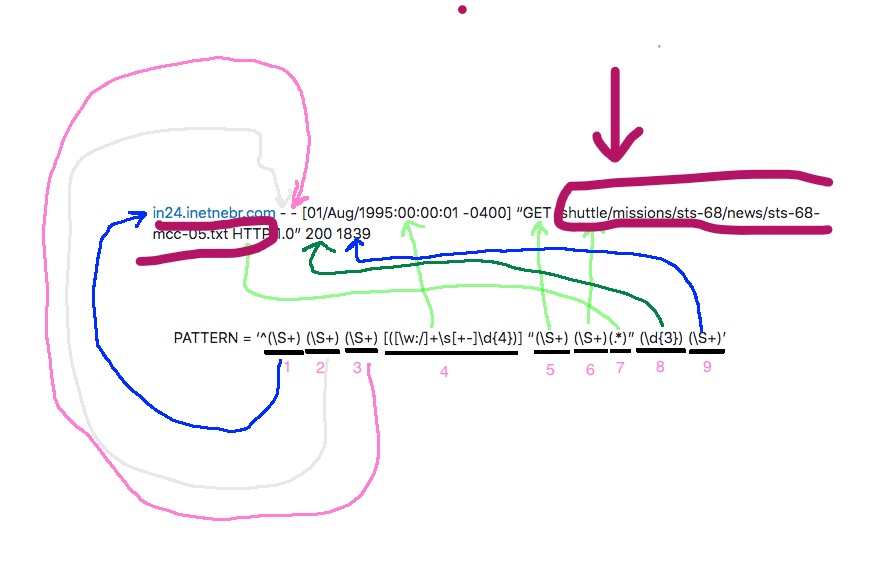
It matches the PATTERN with the “log” text:
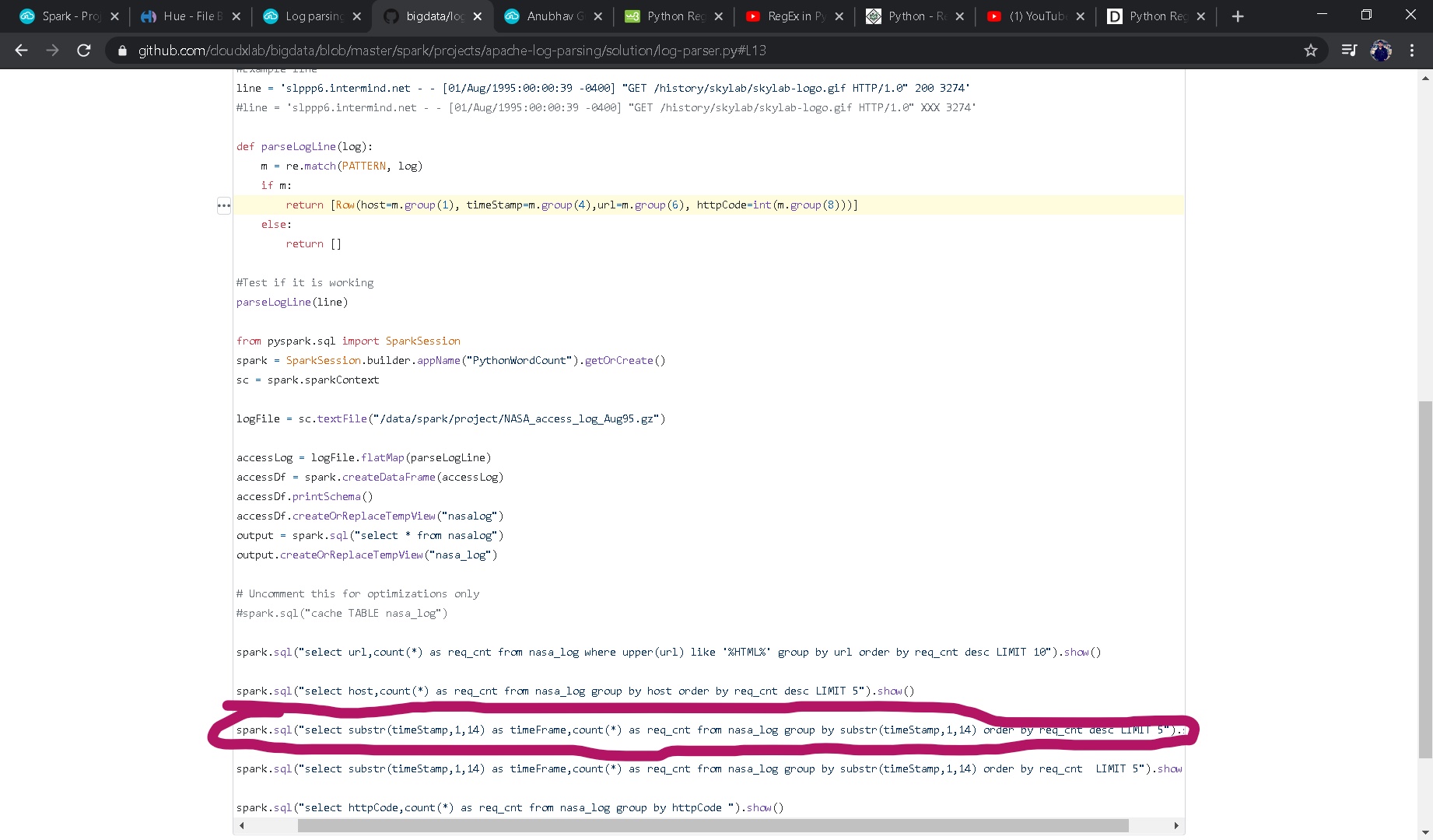
m = re.match(PATTERN, log)
If the match is found then this condition will be true:
if m:
The regular expression “PATTERN” would be having tagged expression or captures. 1 refers to the first capture:
m.group(1)
It returns an array containing the object of Row class. This object of Row class is being created using the constructor of Row with the various arguments such as host, timeStamp and url extracted from the “log” text using the regular expression:
return [Row(host=m.group(1), timeStamp=m.group(4),url=m.group(6), httpCode=int(m.group(8)))]