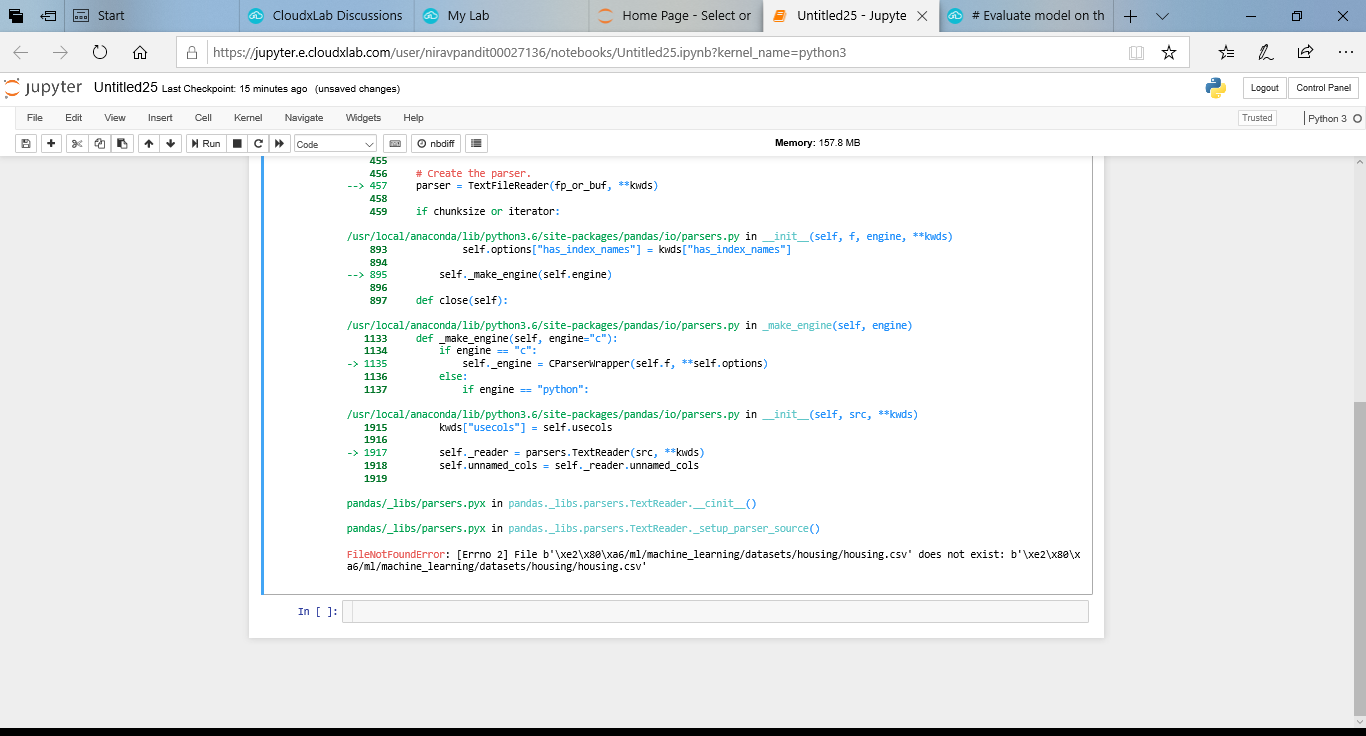
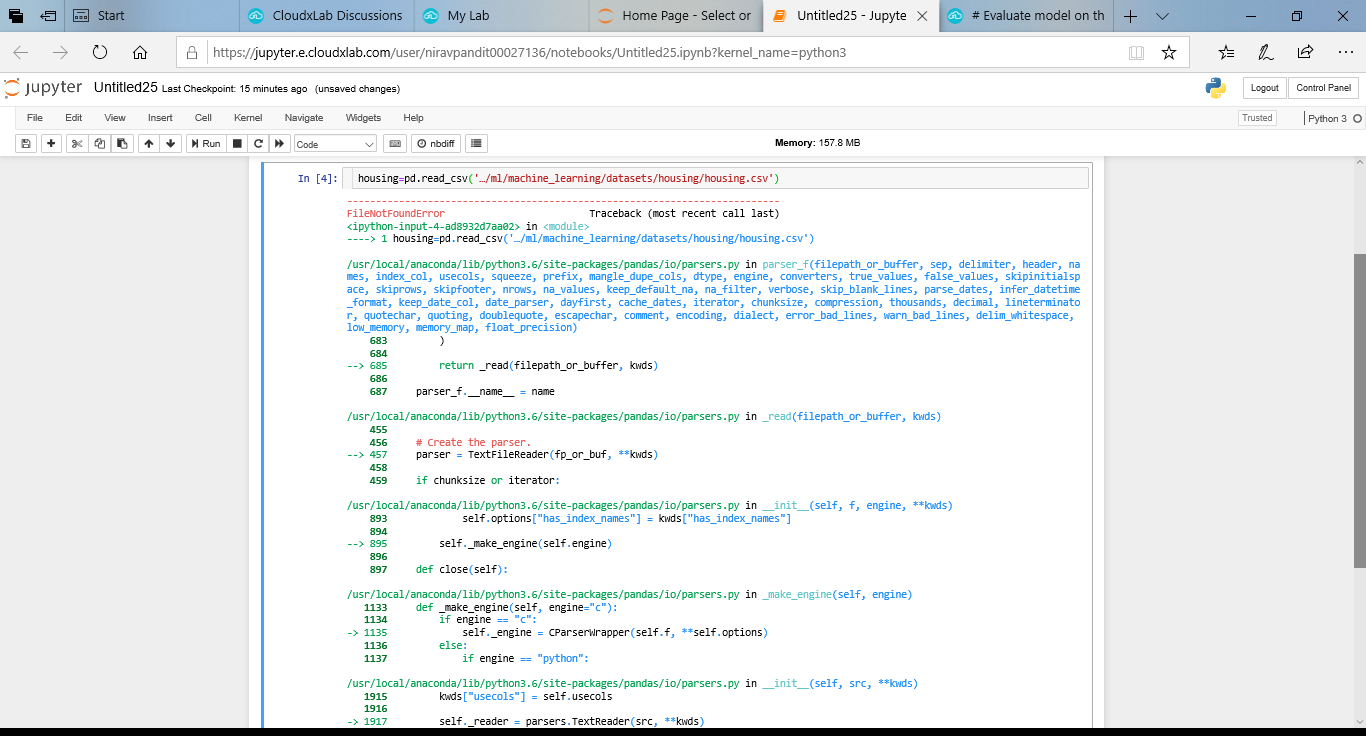
i did not understand why did this happen??
X_test_prepared=full_pipeline.transform(X_test)
KeyError Traceback (most recent call last)
in
1 #Run full pipeline to transform the data
----> 2 X_test_prepared=full_pipeline.transform(X_test)
3 final_predictions = final_model.predict(X_test_prepared)
~\anaconda3\lib\site-packages\sklearn\pipeline.py in transform(self, X)
998 sum of n_components (output dimension) over transformers.
999 “”"
-> 1000 Xs = Parallel(n_jobs=self.n_jobs)(
1001 delayed(_transform_one)(trans, X, None, weight)
1002 for name, trans, weight in self._iter())
~\anaconda3\lib\site-packages\joblib\parallel.py in call(self, iterable)
1027 # remaining jobs.
1028 self._iterating = False
-> 1029 if self.dispatch_one_batch(iterator):
1030 self._iterating = self._original_iterator is not None
1031
~\anaconda3\lib\site-packages\joblib\parallel.py in dispatch_one_batch(self, iterator)
845 return False
846 else:
–> 847 self._dispatch(tasks)
848 return True
849
~\anaconda3\lib\site-packages\joblib\parallel.py in _dispatch(self, batch)
763 with self._lock:
764 job_idx = len(self._jobs)
–> 765 job = self._backend.apply_async(batch, callback=cb)
766 # A job can complete so quickly than its callback is
767 # called before we get here, causing self._jobs to
~\anaconda3\lib\site-packages\joblib_parallel_backends.py in apply_async(self, func, callback)
206 def apply_async(self, func, callback=None):
207 “”“Schedule a func to be run”""
–> 208 result = ImmediateResult(func)
209 if callback:
210 callback(result)
~\anaconda3\lib\site-packages\joblib_parallel_backends.py in init(self, batch)
570 # Don’t delay the application, to avoid keeping the input
571 # arguments in memory
–> 572 self.results = batch()
573
574 def get(self):
~\anaconda3\lib\site-packages\joblib\parallel.py in call(self)
250 # change the default number of processes to -1
251 with parallel_backend(self._backend, n_jobs=self._n_jobs):
–> 252 return [func(*args, **kwargs)
253 for func, args, kwargs in self.items]
254
~\anaconda3\lib\site-packages\joblib\parallel.py in (.0)
250 # change the default number of processes to -1
251 with parallel_backend(self._backend, n_jobs=self._n_jobs):
–> 252 return [func(*args, **kwargs)
253 for func, args, kwargs in self.items]
254
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _transform_one(transformer, X, y, weight, **fit_params)
717
718 def _transform_one(transformer, X, y, weight, **fit_params):
–> 719 res = transformer.transform(X)
720 # if we have a weight for this transformer, multiply output
721 if weight is None:
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _transform(self, X)
547 Xt = X
548 for _, _, transform in self._iter():
–> 549 Xt = transform.transform(Xt)
550 return Xt
551
in transform(self, X)
9 return self
10 def transform(self, X):
—> 11 return X[self.attribute_names].values
~\anaconda3\lib\site-packages\pandas\core\frame.py in getitem(self, key)
2804 if is_iterator(key):
2805 key = list(key)
-> 2806 indexer = self.loc._get_listlike_indexer(key, axis=1, raise_missing=True)[1]
2807
2808 # take() does not accept boolean indexers
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _get_listlike_indexer(self, key, axis, raise_missing)
1550 keyarr, indexer, new_indexer = ax._reindex_non_unique(keyarr)
1551
-> 1552 self._validate_read_indexer(
1553 keyarr, indexer, o._get_axis_number(axis), raise_missing=raise_missing
1554 )
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _validate_read_indexer(self, key, indexer, axis, raise_missing)
1644 if not (self.name == “loc” and not raise_missing):
1645 not_found = list(set(key) - set(ax))
-> 1646 raise KeyError(f"{not_found} not in index")
1647
1648 # we skip the warning on Categorical/Interval
KeyError: “[‘median_house_value’] not in index”
I have dropped the value as Sandeep Giri sir said but it shows me error.
#Get predictors and labels from the test set
#Predictors
X_test=strat_test_set.drop(“median_house_value”,axis=1)
#labels
y_test=strat_test_set[“median_house_value”].copy()