Please explain the concept when why and where to use this
COALESCE , REPARTITION , and REPARTITION_BY_RANGE
note : – i checked the apache spark documentations for this but did not get completely

Please explain the concept when why and where to use this
COALESCE , REPARTITION , and REPARTITION_BY_RANGE
note : – i checked the apache spark documentations for this but did not get completely
Coalesce litterally means come together. It is in SQL as well as SparkSQL means the same.
In case of Spark SQL, it gives the first non-null value.
You can test by first launching spark-shell and running the following command
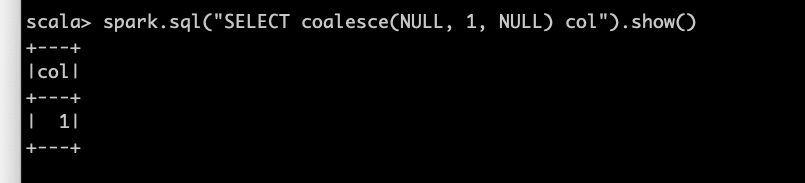
spark.sql("SELECT coalesce(NULL, 1, NULL) col").show()
This query SELECT coalesce(NULL, 1, NULL) basically displays the first non-null i.e. 1.
My query is not what is Coalesce this is known is SQL ; here question is about performance tuning section of SPARK SQL ; why and when we go for repartitioning and
REPARTITION_BY_RANGE ; as in your lecture we studied about partitioning about RDD ; but here i am not able to understand
this is the below link
https://spark.apache.org/docs/3.0.1/sql-performance-tuning.html
I have found an article which might help. Please check it out.