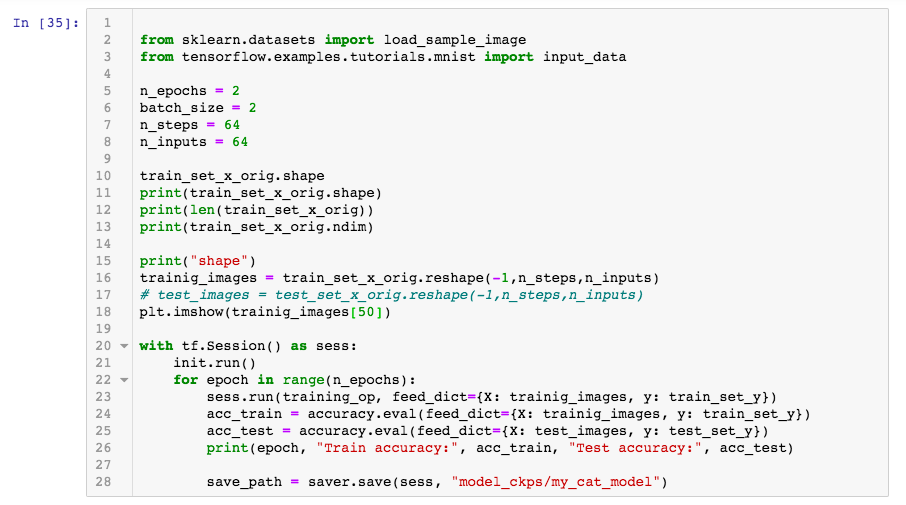
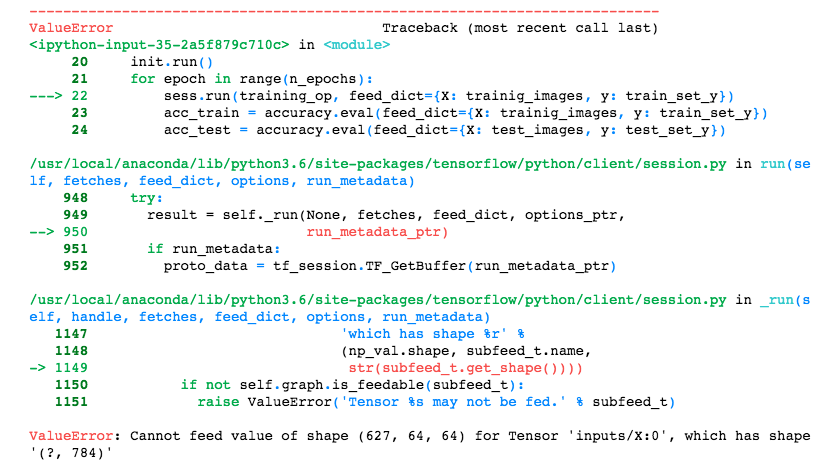
Hello,
can someone guide me what to correct in this code?

hi,
still facing issue?
thanks
Hello All
Can somebody check my code below and provide me some pointers. My loss is too high.
Thanks for your Time. - Srini
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras as k
import h5py
from PIL import Image
%matplotlib inline
#train_catvnoncat.h5 - a training set of images labeled as cat (y=1) or non-cat (y=0)
#test_catvnoncat.h5 - a test set of images labeled as cat or non-cat
#Each image is of shape (num_px, num_px, 3) where 3 is for the 3 channels (RGB). Thus, each image is square (height = num_px) and (width = num_px)
#Load training data
train_dataset = h5py.File(’/cxldata/datasets/project/cat-non-cat/train_catvnoncat.h5’, ‘r’)
print(train_dataset.keys())
train_set_x_orig = np.array(train_dataset[‘train_set_x’])
train_set_y_orig = np.array(train_dataset[‘train_set_y’])
print(train_set_x_orig.shape)
print(train_set_y_orig.shape)
#Load test data
test_dataset = h5py.File(’/cxldata/datasets/project/cat-non-cat/test_catvnoncat.h5’, ‘r’)
print(test_dataset.keys())
test_set_x_orig = np.array(test_dataset[‘test_set_x’])
test_set_y_orig = np.array(test_dataset[‘test_set_y’])
print(test_set_x_orig.shape)
print(test_set_y_orig.shape)
type(test_dataset[‘list_classes’])
np.array(test_dataset[‘list_classes’][])
print(type(test_dataset[‘list_classes’][:]))
classes = np.array(test_dataset[‘list_classes’][:])
print(type(classes))
train_set_y = train_set_y_orig.reshape(1, train_set_y_orig.shape[0])
test_set_y = test_set_y_orig.reshape(1, test_set_y_orig.shape[0])
print(train_set_y.shape)
print(test_set_y.shape)
index = 50
plt.imshow(train_set_x_orig[index])
y = train_set_y[:, index]
y_class = classes[np.squeeze(train_set_y[:,index])].decode(“utf-8”)
print(y)
print(y_class)
train_set_x_orig.shape
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1)
train_set_x_flatten.shape
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1)
test_set_x_flatten.shape
X_valid, X_train = train_set_x_orig[:40]/255, train_set_x_orig[40:]/255,
y_valid, y_train = train_set_y_orig[:40], train_set_y_orig[40:]
print(X_valid.shape, X_train.shape, y_valid.shape, y_train.shape)
model = k.models.Sequential()
model.add(k.layers.Flatten(input_shape=[64, 64, 3]))
model.add(k.layers.Dense(300, activation=‘relu’))
model.add(k.layers.Dense(200, activation=‘relu’))
model.add(k.layers.Dense(100, activation=‘relu’))
model.add(k.layers.Dense(1, activation=‘sigmoid’))
model.summary()
model.compile(loss=‘binary_crossentropy’,
optimizer=‘adam’,
metrics = [‘accuracy’])
history = model.fit(X_train,
y_train,
epochs=100,
validation_data=(X_valid, y_valid))
model.evaluate(test_set_x_orig, test_set_y_orig)
@CloudX team
Since there are no replies, I would at least request some guidance on - if the following input shapes are the right inputs for the model below? I really appreciate your help as I have been stuck on this problem for almost 3 days.
X_valid, X_train = train_set_x_orig[:20]/255, train_set_x_orig[20:]/255
X_test = test_set_x_orig[:]/255
y_valid, y_train = train_set_y_orig[:20]/255, train_set_y_orig[20:]/255
print(X_valid.shape, X_train.shape, y_valid.shape, y_train.shape, X_test.shape, test_set_y_orig.shape)
// output (20, 64, 64, 3) (189, 64, 64, 3) (20,) (189,) (50, 64, 64, 3) (50,)
model = k.models.Sequential()
model.add(k.layers.Flatten(input_shape=[64, 64, 3]))
model.add(k.layers.Dense(300, activation=‘relu’))
model.add(k.layers.Dense(200, activation=‘relu’))
model.add(k.layers.Dense(100, activation=‘relu’))
model.add(k.layers.Dense(1, activation=‘sigmoid’))
model.summary()
Model: “sequential”
flatten (Flatten) (None, 12288) 0
dense (Dense) (None, 300) 3686700
dense_1 (Dense) (None, 200) 60200
dense_2 (Dense) (None, 100) 20100
Total params: 3,767,101
Trainable params: 3,767,101
Non-trainable params: 0
Hi.
The below model can be used for you task.
Where VGG3 is the The three-block VGG model with 128 filters.
Note :- The shape of the images depends on the images to images. But you can surely augments the image data.
The model architecture is up to you to decide after the explorations and experimentations!
You should refer the VGG16.
You can refer to the below :-
https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
https://keras.io/api/applications/#vgg16
https://www.kaggle.com/bulentsiyah/dogs-vs-cats-classification-vgg16-fine-tuning
Satyajit - we have not covered the convolutions yet! I am trying to do it base ANN for now. I think the problem I am facing is with understanding the input shapes. Any help will be appreciated in helping me understand how the shapes should be aligned and why they should be.
Srini