A very good question and your assumptions are right. Very quick answer is “Yes it is possible but you have to be very careful.”
Let me try to give a more detailed answer.
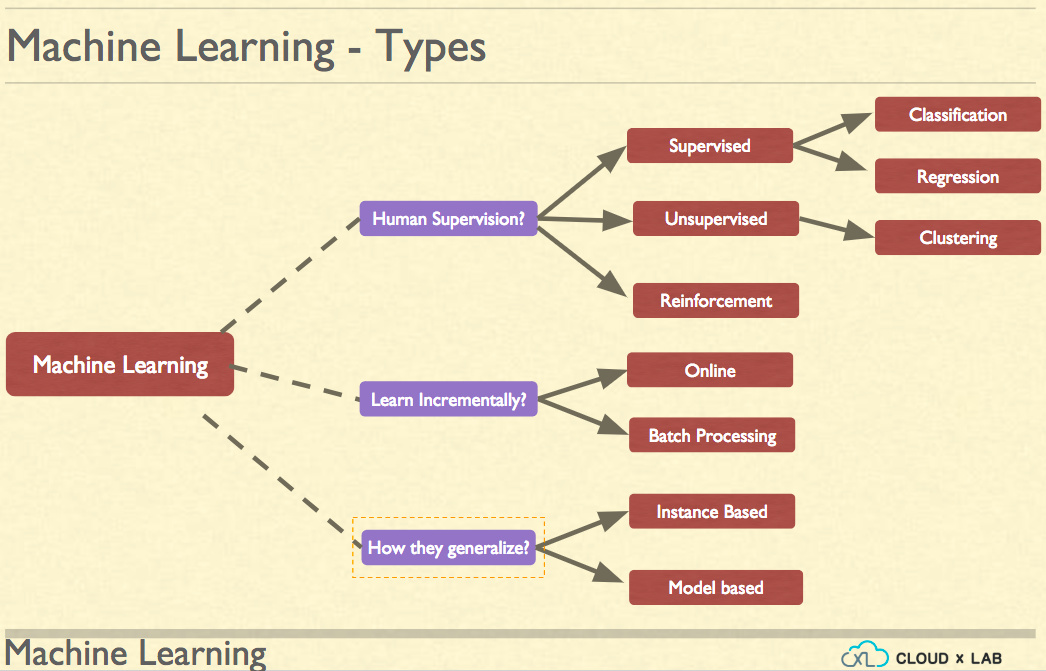
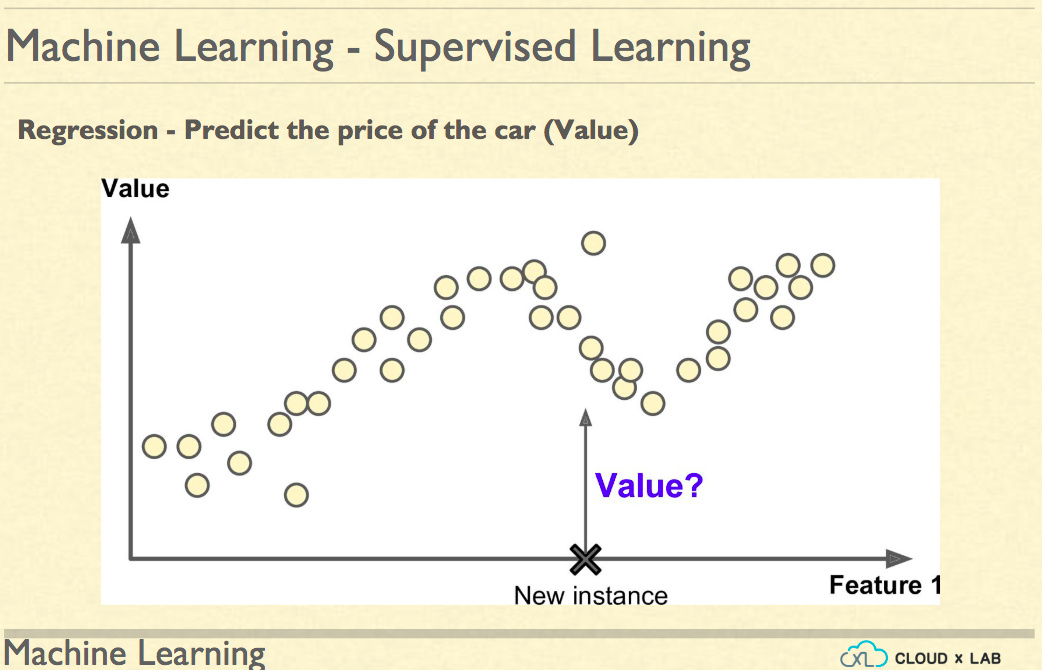
The supervised Machine Learning is essentially estimating the unseen value(s) based on the past data. If the value is numeric then type of supervised machine learning is further classified as Regression and if is categorical i.e. discrete fixed set of values (such as High, Low, Medium) it is categorised as Classification.
In case of Regression, the prediction will be a numeric value while in case of Classification the prediction is mostly probabilities of various categories and in some algorithms, the prediction is just a class instead of probabilities.
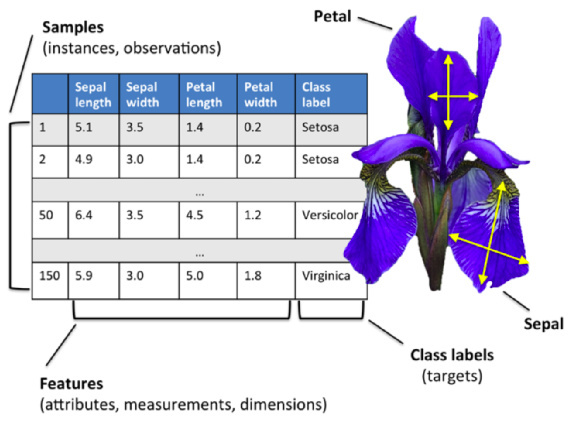
Also, just to keep things in perspective, let me give you an overview of how to frame a machine learning problem. First, convert your data into a table such that there are one or more columns whose value you would need to predict. it is called label or target. The rest of the columns are called features/properties/attributes. Every data point is called instance and is represented as a row.
Now, the question is how do we gain confidence such that we can put machine learning in the mission-critical use cases. Here are some of my ideas:
1. Preprocessing Data
Go through the data and observe the variance (or standard deviation) in various features to gain a perspective. Know the worst case scenarios. Also, do the outlier detection using any of the unsupervised techniques such as k-means. This will help you in two ways. One, in getting the understanding of how much is the tolerance and second if there outliers.
2. Choosing Right Metrics
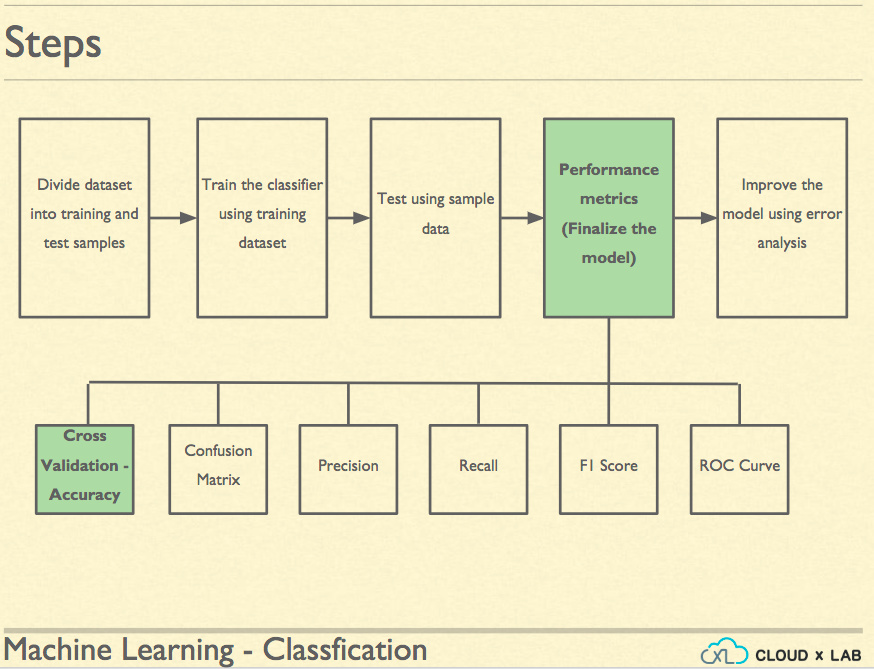
Before an algorithm starts to give predictions, it needs to be trained. In scikit-lean, we basically call fit() method with features and target columns of the past instances (or records) and then we call to predict the future values using predict() method on the trained model with unseen data as the argument.
Now, how would we know that our model is working or not working? And if working how well it is going and how stable it is. We break down the past data into two parts - training and test. On the training set, we train and on test set we test. Further, we use cross-validation on the training set such that we can compare various algorithms.
So, we train various algorithms and compare their performance on the test set. If we are doing regression, we can compare the mean square error between the actual and predicted values and see how well are the predictions. Also, we often compute the standard deviation in predictions. If there is a huge SD of a particular algorithm, we may avoid it if it might cross our expectations.
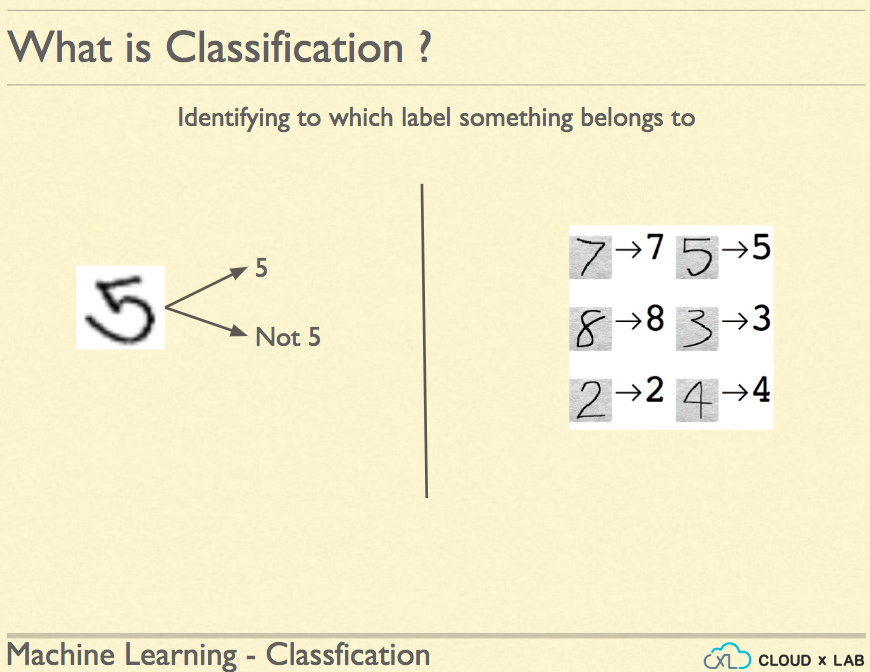
If we are doing the classification, then the challenge is bigger. First, how do we sum up the overall error? Say, we come up accuracy such that we just divide the correctly classified by total instances. This sounds great but say, we are predicting say 5 or not 5 in the MNIST dataset. The MNIST dataset is a database of 70000 handwritten digits along with their correct labels. Say, your algorithm is predicting accurately 90% whether a digit is 5 or it is not 5. Will you trust such an algorithm? You should not because if there are only 10% digits that 5 in the MNIST database. Such an algorithm could be a fraud because it could simply return NOT 5 for every digit making the accuracy 90%.
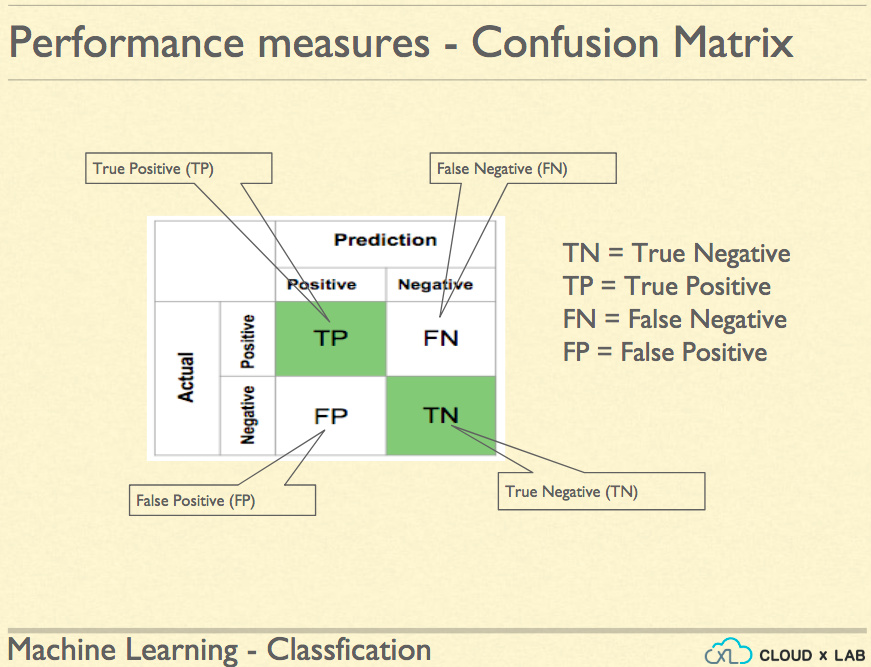
So, we need better measures of performance than accuracy. We first compute the confusion table. Confusion table basically lists the counts of all misclassification actual vs predicted category wise.
- How many were 5 but predict as not 5.
- How many were 5 and predicted as 5
- How many were not 5 and predict as not 5.
- How many were not 5 but predicted as 5
Once we are done creating the confusion table, we compute the recall rate and precision.
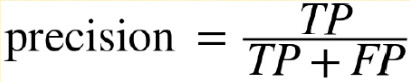
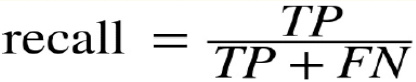
We use the recall rate as the measure if making a mistake is not a problem and we use precision as the measure when making the mistakes is not tolerable. We can come up with our threshold for precision and use that if our requirement very mission critical.
Say, if we are tagging the video as baby safe, we need to have high precision because we can’t afford to make mistakes. If we say trying to predict if someone has shop-lifted, we can go for recall because we can always go for a physical check.
If we want to for best of both recall and precision, we go for the f1 score which is as follows:
3. Understand the underpinnings
3.1 Educate your self
Sometimes, we aren’t confident about launching a particular model because we don’t understand the underlying model. So, it is always advised to learn the algorithm and strategy. Courses like this might help.
3.2 Visualize
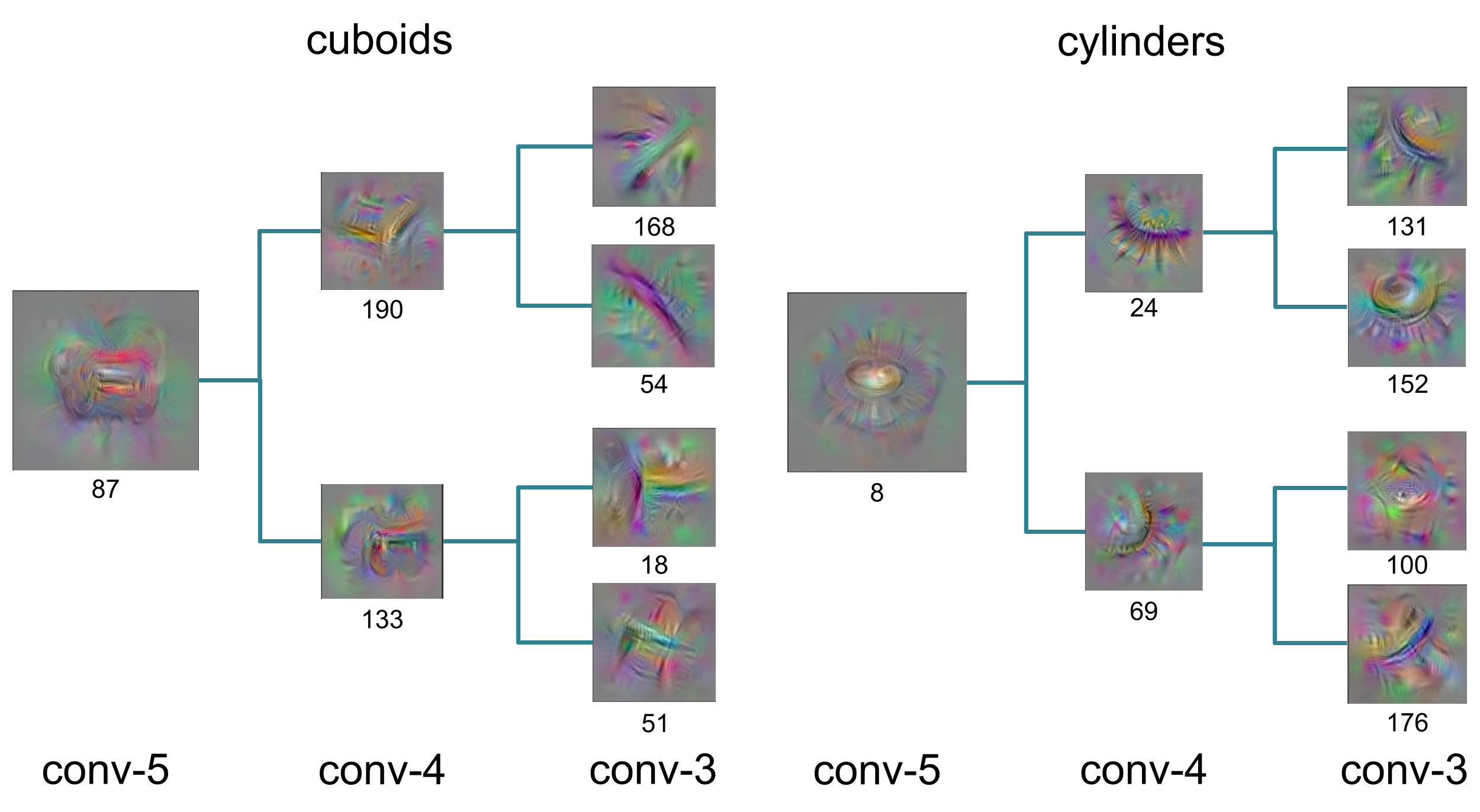
If you are using the complex models such as Neural Networks, it becomes difficult to gain trust. Try to visualize and observe each layers outcome. That generally helps in improving and gain trust.
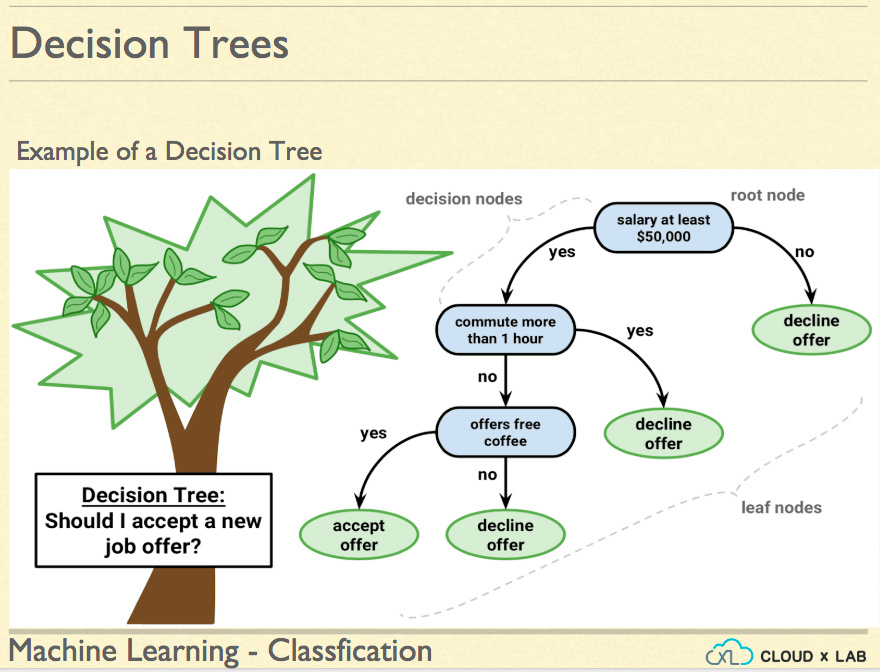
3.3 Use Simpler Models
There are two kinds of models. One is called a black box and another white box. If it is okay to let go of performance a bit settle down for a model like decision trees over the neural network. A model like decision tree is easier to visualize and hence boosts confidence as we know the underpinnings.