
Q. Should we have to do stratified sampling ALWAYS? or we can do normal splitting.
We generally require stratified sampling using that feature as strata which has a strong correlation with the output and the distribution that feature’s values has imblance.
For example, let us say we are predicting the house prices in a locality (see this dataset https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html)

When you look at the correlations between various parameter using the following command: corr_matrix[“median_house_value”].sort_values(ascending=False)
You get a result:
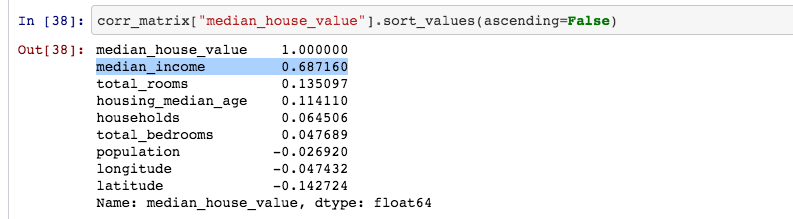
Do you see that the median_income has the most impact on the median_house_value?
Now, let us see distribution of median_income:
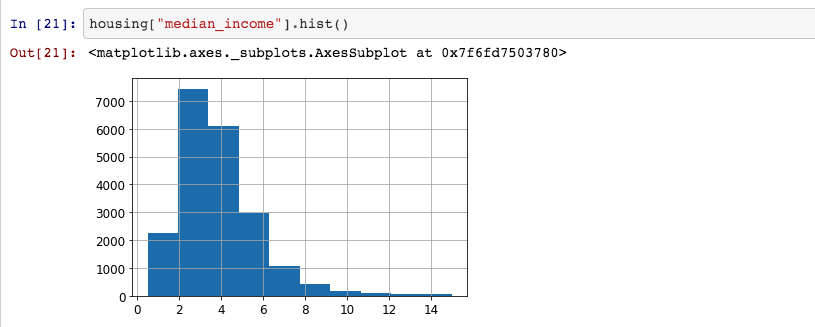
Do you notice that most values are clustered around 2-5 thousand dollars.
So, the median_income impacts the output ‘house_value’ the maximum and also has imbalance in values. This means that when we select the test data randomly, the various values of median_income may not go in output. So, when we are selecting 80% in training dataset, the maximum representaion of the instances will be from 2-5 thousand dollars and the instances below 2 and above 5 may not be available in the training dataset. Therefore, the model will never learn from instances of poor or rich locality and therefore could be more biased. Such a biased model will not be able predict the house prices in very rich or very poor localities.
Therefore, to ensure that the outcome has representation from every strata we do the stratified sampling.
I hope I was able to make sense.
1 Like
Certainly an enlightening explaination.
1 Like
ok sir thank you .
I was doing the wine quality analysis and there without stratified sampling I was getting mean error of 0.6 in the RandomForestTree model after cross validation. Should I need to be more accurate.
I have done with stratified sampling on the basis of alcohol which shows strong correlation giving error 0.59 which has a diff of 0.1 from previous.